
Lerntext Biomoleküle (pdf)
Roland Heynkes 15.11.2019, CC BY-SA-4.0 DE
If you cannot read German-language texts, you could try a translation into your native language with DeepL.
| Aufgaben zur Erarbeitung des Lerntextes bzw. zur Lernkontrolle | |
|---|---|
| 1 | Definiere den Begriff Biomolekül! |
| 2 | Nenne die Biomoleküle unter unseren Nährstoffen! |
| 3 | Beschreibe, wofür unsere Zellen die aus unseren Nährstoffen gewonnenen Zucker, Lipide und Aminosäuren nutzen! |
| 4 | Nenne die Monomere, in welche die in unserer Nahrung vorhanderen Kohlenhydrate, Lipide und Proteine durch die Verdauung zerlegt werden! |
| Hier geht es zu den Antworten. | |
Lebewesen bestehen aus Mineralstoffen, Wasser und Biomolekülen.
| Biomoleküle sind hauptsächlich aus Kohlenstoff und Wasserstoff bestehende, von Lebewesen produzierte Moleküle. |
Während Pflanzen alle ihre Biomoleküle selbst herstellen, müssen Pilze und Tiere energiereiche Biomoleküle als Nahrung aufnehmen.

|
|---|
| Roland Heynkes, CC BY-SA 3.0 |
Wie alle Tiere brauchen auch wir Menschen nicht nur die in Nährstoffen steckende chemische Energie. Einen Teil unserer Nährstoffe nutzen wir als Baustoffe für unseren Baustoffwechsel. Dazu gehören auch sogenannte Cofaktoren, die viele unserer Enzyme für ihre Funktionen benötigen. Als Cofaktoren oder deren Vorstufen nutzen unsere Zellen Vitamine.
| Wie wir unsere Nährstoffe nutzen | ||||
|---|---|---|---|---|
| Energiestoffwechsel | BaustoffwechselBaustoffwechsel | |||
| Kohlenhydrate | ja | nein | ||
| Fett u.a. Lipide | ja | ja | ||
| Proteine | kaum | ja | ||
| Vitamine | nein | ja | ||
| Mineralstoffe | nein | ja | ||
| Roland Heynkes, CC BY-SA 3.0 | ||||
Essentielle Aminosäuren und Fettsäuren gewinnen wir durch die Verdauung von Proteinen zu Aminosäuren sowie Lipiden zu Glycerin und Fettsäuren. Wir zerlegen (verdauen) große fremde Biomoleküle in Bausteine, aus denen unsere Zellen ihre eigenen Biomoleküle aufbauen können.
| Verdauung unserer Makronährstoffe |
|---|
 |
Die in unserer Nahrung ebenfalls vorhandenen Nukleinsäuren werden von uns nicht als Nährstoffe genutzt. Sie werden aber im Dünndarm von verschiedenen Nukleasen erst in Nukleotide und anschließend in Nukleobasen, Phosphat und Ribose oder Desoxyribose zerlegt, damit keine fremden Erbinformationen in uns wirksam werden.
Mehr Informationen und ausführlichere Erklärungen über unsere Nährstoffe enthält der Lerntext Nahrung.
Die in unserer Nahrung vorhandenen großen Biomoleküle sind Polymere. Sie bestehen aus vielen (poly) Bausteinen, den Monomeren (mono = 1). Hängt man zwei Monomere aneinander, so erhält man ein Dimer (di = 2). Mehrere (oligo) Monomere ergeben ein Oligomer. Und viele (poly) Monomere bilden ein Polymer.
Die folgende Tabelle soll die wichtigsten Fachbegriffe im Zusammenhang mit den Biopolymeren übersichtlich zusammenfassen.
| wichtige Biopolymere und ihre Monomere (Bausteine) | |||||
|---|---|---|---|---|---|
| Biopolymer-Typ | Monomer (eins) | Dimer (zwei) | Oligomer (mehrere) | Polymer (viele) | |
| Peptide | Aminosäure | Dipeptid | Oligopeptid | Polypeptid (Protein) | |
| Kohlenhydrate | Monosaccharid (Einfachzucker) z.B. Glucose | Disaccharid (Zweifachzucker) z.B. Maltose | Oligosaccharid (Mehrfachzucker) z.B. Raffinosen | Polysaccharid (Vielfachzucker) z.B. Stärke | |
| Erbmaterial | Nukleotid | Dinukleotid (z.B. NAD) | Oligonukleotid | Nukleinsäuren (DNA oder RNA) | |
Proteine, Polysaccharide und die großen Nukleinsäuren nennt man aufgrund ihrer Größe auch Makromoleküle. Obwohl sie weitaus kleiner sind, werden dazu meistens auch die Lipide gezählt, die ebenfalls zu groß sind, um unverdaut unsere Darmschleimhaut zu passieren.
In den folgenden Kapiteln werden diese wichtigen Klassen von Biomolekülen näher betrachtet.
| Aufgabe zur Erarbeitung des Lerntextes bzw. zur Lernkontrolle | |
|---|---|
| 5 | Beschreibe die Eigenschaften der funktionellen Gruppen Hydroxygruppe, Aminogruppe und Carboxygruppe! |
| Hier geht es zur Antwort. | |
Funktionelle Gruppen nennt man insbesondere in der organischen Chemie Atomgruppen, welche die Stoff-Eigenschaften und das Reaktionsverhalten des Gesamtmoleküls beeinflussen. Wichtige Beispiele sind die früher Hydroxylgruppe genannte Hydroxygruppe, die Aminogruppe, die Carboxylgruppe, die Carbonylgruppe, die Aldehydgruppe und die Ketogruppe.
| die Hydroxygruppe |
|---|
 |
| anonym, public domain |
Hydroxylgruppe bzw. Hydroxygruppe nennt man eine funktionelle Gruppe, die lediglich aus einem Sauerstoff-Atom und einem daran gebundenen Wasserstoffatom besteht. Weil das gemeinsame Elektronenpaar stark zum Sauerstoff hin gezogen wird, ist dieser in der Hydroxygruppe partiell negativ geladen, während der partiell positiv geladene Wasserstoff als Proton abgespalten werden kann. Die Hydroxygruppe ist also polar, reaktionsfreudig und leicht sauer. Der partiell negativ geladene Sauerstoff kann aber auch als Base fungieren und an einem seiner beiden freien Elektronenpaare beispielsweise ein Proton binden. Außerdem zieht eine Hydroxygruppe meistens das gemeinsame Elektronenpaar zu sich, wenn sie an ein Kohlenstoff-Atom gebunden ist.
| die Aminogruppe |
|---|
 |
| anonym, public domain |
Aminogruppe nennt man eine funktionelle Gruppe, in der zwei Wasserstoffatome über einfache Elektronenpaar-Bindungen an ein Stickstoff-Atom gebunden sind (-NH2). Das Stickstoff-Atom zieht die gemeinsamen Elektronenpaare etwas zu sich hin, aber nicht stark genug, um eine Abspaltung von Protonen wahrscheinlich zu machen. Der partiell negativ geladene Stickstoff kann aber als Base fungieren und an seinem freien Elektronenpaar beispielsweise ein Proton binden. Außerdem kann das Stickstoff-Atom einer Aminogruppe sein freies Elektronenpaar zu dem Kohlenstoff-Atom herüber klappen, über das sie an den Rest des Moleküls gebunden ist.
| die Carboxygruppe |
|---|
 |
| anonym, public domain |
Carboxygruppe oder veraltet Carboxylgruppe heißt eine leicht sauer (im chemischen Sinne) reagierende funktionelle Gruppe (-COOH) vieler organisch-chemischer Moleküle, die aus einem Kohlenstoff-Atom (C) besteht, an dem eine Hydroxylgruppe (-OH) und über eine Doppelbindung ein Sauerstoff-Atom (=O) hängen.
| die Carbonylgruppe |
|---|
 |
| anonym, public domain |
Carbonylgruppe nennt man eine funktionelle Gruppe, die lediglich aus einem Sauerstoff-Atom besteht, welches über eine Doppelbindung (zwei Elektronenpaarbindungen zwischen den beiden Atomen) an ein Kohlenstoff-Atom gebunden ist (>C=O), das seinerseits mit zwei weiteren Atomen verbunden ist. In dieser zieht das Sauerstoff-Atom die beiden Elektronenpaare stark zu sich hin und sorgt so für einen Elektronenmangel, also eine positive Teilladung am Kohlenstoff-Atom. Dieses positiv polarisierte Kohlenstoff-Atom zieht negative Ladungen und Teilladungen an und wird dadurch zum Ziel nucleophiler Angriffe. Wegen seiner positiven Polarisierung zieht dieses Kohlenstoff-Atom seinerseits verstärkt an den Elektronenpaaren, welches es sich mit den benachbarten Atomen teilt. Bei diesen beiden Nachbaratomen kann es sich um zwei Kohlenstoff-Atome handeln, und dann nennt man diese Carbonylgruppe eine Ketogruppe. Ist das Kohlenstoff-Atom an ein Kohlenstoff-Atom und an ein Wasserstoffatom gebunden, dann spricht man von einer Aldehydgruppe.
| die Aldehydgruppe |
|---|
 |
| anonym, public domain |
Aldehydgruppe nennt man eine funktionelle Gruppe, in der an ein Kohlenstoff-Atom ein Wasserstoffatom und über eine Elektronenpaar-Doppelbindung ein Sauerstoff-Atom gebunden ist (-CH=O). Im Grunde enthält eine Aldehydgruppe ihrerseits wiederum eine funktionelle Gruppe, nämlich eine Carbonylgruppe. Die Carbonylgruppe bestimmt wesentlich die Eigenschaften der Aldehydgruppe und macht sie polar, reaktionsfreudig und schwach sauer. In dieser zieht das Sauerstoff-Atom die beiden Elektronenpaare stark zu sich hin und sorgt so für einen Elektronenmangel, also eine positive Teilladung am Kohlenstoff-Atom. Dieses positiv polarisierte Kohlenstoff-Atom zieht negative Ladungen und Teilladungen an und wird dadurch zum Ziel nukleophiler Angriffe. Wegen seiner positiven Polarisierung zieht dieses Kohlenstoff-Atom seinerseits verstärkt an dem Elektronenpaar, welches es sich mit dem Wasserstoffatom teilt. Dadurch kann dieses leichter als Proton abgespalten werden. Außerdem zieht eine Aldehydgruppe meistens das gemeinsame Elektronenpaar zu sich, wenn sie an ein Kohlenstoff-Atom gebunden ist.
| die Ketogruppe |
|---|
|
|
| anonym, public domain |
Ketogruppe nennt man eine funktionelle Gruppe, die eigentlich nur aus einem Sauerstoff-Atom besteht, welches über eine Doppelbindung (zwei Elektronenpaarbindungen zwischen den beiden Atomen) an ein Kohlenstoff-Atom gebunden ist (>C=O), das seinerseits mit zwei weiteren Kohlenstoff-Atomen verbunden ist. Im Grunde enthält eine Ketogruppe ihrerseits wiederum eine funktionelle Gruppe, nämlich eine Carbonylgruppe. Die Carbonylgruppe bestimmt wesentlich die Eigenschaften der Ketogruppe und macht sie polar sowie relativ reaktionsfreudig. In dieser zieht das Sauerstoff-Atom die beiden Elektronenpaare stark zu sich hin und sorgt so für einen Elektronenmangel, also eine positive Teilladung am Kohlenstoff-Atom. Dieses positiv polarisierte Kohlenstoff-Atom zieht negative Ladungen und Teilladungen an und wird dadurch zum Ziel nucleophiler Angriffe. Wegen seiner positiven Polarisierung zieht dieses Kohlenstoff-Atom seinerseits verstärkt an den Elektronenpaaren, welche es sich mit den benachbarten Kohlenstoff-Atomen teilt.
| Aufgaben zur Erarbeitung dieses Kapitels bzw. zur Lernkontrolle | |
|---|---|
| 6 | Nenne die Eigenschaft, an der man Lipide relativ leicht erkennen kann! |
| 7 | Erkläre die Ursache für diese Eigenschaft! |
| 8 | Erkläre, warum die teuren fettreduzierten Nahrungsmittel nur für die Hersteller eine gute Idee sind! |
| Hier geht es zu den Antworten. | |
Lipide sind in Wasser schlecht lösliche Moleküle wie Fette und Cholesterin. Aus Lipiden bauen unsere Zellen ihre Membranen und in ihnen speichern wir chemische Energie. Lipide lösen sich schlecht in Wasser, weil sie ganz oder größtenteils unpolar sind. Die Ursache dafür ist, dass die unpolaren Anteile der Lipide nur aus Kohlenstoff- und Wasserstoffatomen bestehen, deren Elektronegativität praktisch gleich ist, sodass die Atombindungen (das Bindungselektronenpaar) symmetrisch und die elektrischen Ladungen gleichmäßig verteilt bleiben. Normalerweise haben aber Lipide auch einen polaren, wasserlöslichen Molekülteil, mit dem sie eine Grenzschicht zu Wasser bilden.
| zwei typische Lipide | |
|---|---|
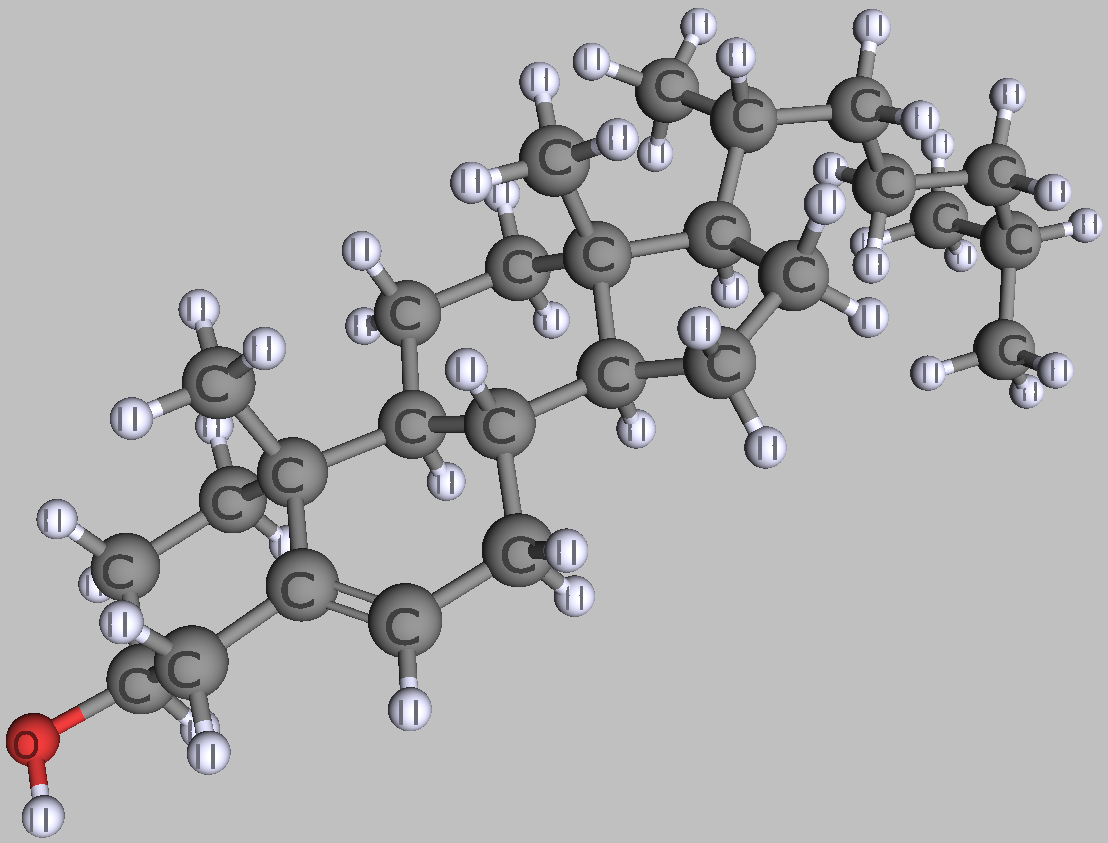 |
 |
| Cholesterin | Palmitinsäure |
| Roland Heynkes, CC BY-SA-4.0 | |
| Die folgenden Links führen zu selbst manipulierbaren, dreidimensionalen JSmol-Darstellungen von Cholesterin, Palmitinsäure und der Omega-3-Fettsäure Docosahexaensäure. | |
Auf einer eigenen Seite kann man sich mittels dreier selbst manipulierbarer, dreidimensionaler JSmol-Darstellungen die Strukturen von Cholesterin, Palmitinsäure und der Omega-3-Fettsäure Docosahexaensäure von allen Seiten ansehen und diese Lipid-Moleküle dadurch besser verstehen.
Schokolade, Wurst und Käse sieht man nicht unbedingt an, dass sie viel Fett enthalten. Viel Fett und andere Lipide enthaltende tierische Nahrungsmittel sind auch Speck, Schinken, Sahne, Butter und Bratfett. Viel Fett enthaltende pflanzliche Nahrungsmittel sind z.B. Nüsse, Margarine und Pflanzenöle. Als Öle bezeichnet man Fette, die bei Raumtemperatur flüssig sind.
Viele Kinder bevorzugen auch fettreiche Nahrungsmittel wie Pommes und Bratwurst. Unser Steinzeit-Körper bevorzugt höchstwahrscheinlich deshalb von Natur aus energiereiche Nahrung, weil die Menschheit in der Vergangenheit viel häufiger mit Hunger als mit Nahrungsüberfluss zu kämpfen hatte. Vielleicht mögen Menschen auch deshalb fetthaltige Nahrung, weil wir manche Vitamine nur mit Fett aufnehmen können. Fettreiche Nahrung ist außerdem besonders lecker, weil Fett ein wichtiger Geschmacksträger ist.
Unsere Nahrung sollte nicht zu fettarm sein, weil wir Fett als wichtigen Baustoff für unseren Körper, für die Aufnahme bestimmter Vitamine und als Geschmacksträger brauchen. Darum werden Menschen auch nicht wirklich satt, bevor sie ausreichend Fett gegessen haben. Enthält unsere Nahrung zu wenig Fett, dann essen wir mehr und damit vor allem mehr Zucker. Deshalb kann eine zu fettarme Nahrung sogar dick machen, wenn man zu den vielen Menschen gehört, die überschüssige Energie in Fettzellen speichern. Dickmacher Nummer 1 ist nach dem heutigen Stand der Forschung nicht das Fett, sondern Zucker. Und nicht Cholesterin-reiche Nahrung führt zu hohen Cholesterin-Konzentrationen, sondern zuviel Zucker.
| Aufgaben zur Erarbeitung dieses Kapitels bzw. zur Lernkontrolle | |
|---|---|
| 9 | Beschreibe den allgemeinen Aufbau aller Kohlenhydrate! |
| 10 | Nenne die Unterschiede zwischen Zuckern und anderen Kohlenhydraten! |
| 11 | Erkläre, warum Zucker fast immer schädlich, Zellulose jedoch immer und Stärke in bestimmten Situationen nützlich für uns sind! |
| 12 | Nenne die beste und vielleicht einzig funktionierende Möglichkeit, nicht süchtig nach Zucker zu werden! |
| Hier geht es zu den Antworten. | |
Kohlenhydrate wie Zucker, Stärke und Glycogen dienen Lebewesen als Energiequelle. Pflanzen und Bakterien bauen aus Kohlenhydraten ihre Zellwände und auch tierische Zellen haben zu verschiedenen Zwecken viele Kohlenhydrate auf ihren Zelloberflächen. Für Menschen unverdauliche Kohlenhydrate sind für uns wichtig als Ballaststoffe.
Schon der Name Kohlenhydrat lässt erkennen, dass wir es hier mit Molekülen zu tun haben, in denen es pro Kohlenstoff-Atom (C) ein Sauerstoff-Atom (O) und zwei Wasserstoff-Atome (H) gibt. Die allgemeine Formel für Kohlenhydrate heißt daher (COH2)n.
Kohlenhydrate sind Moleküle mit mindestens zwei Hydroxylgruppen (-O-H) und einer Aldehyd- (CH=O) oder Ketogruppe (R-CO-R). Chemisch heißen sie deshalb auch Hydroxyaldehyde oder Hydroxyketone. Wie Zucker und die Monomere polymerer Kohlenhydrate im Prinzip aussehen, zeigen folgende Bilder von zwei Versionen (Konformationen) des einfachsten aller Kohlenhydrate.
| zwei Formen des einfachsten Kohlenhydrates Glycerinaldehyd in räumlicher Darstellung | |
|---|---|
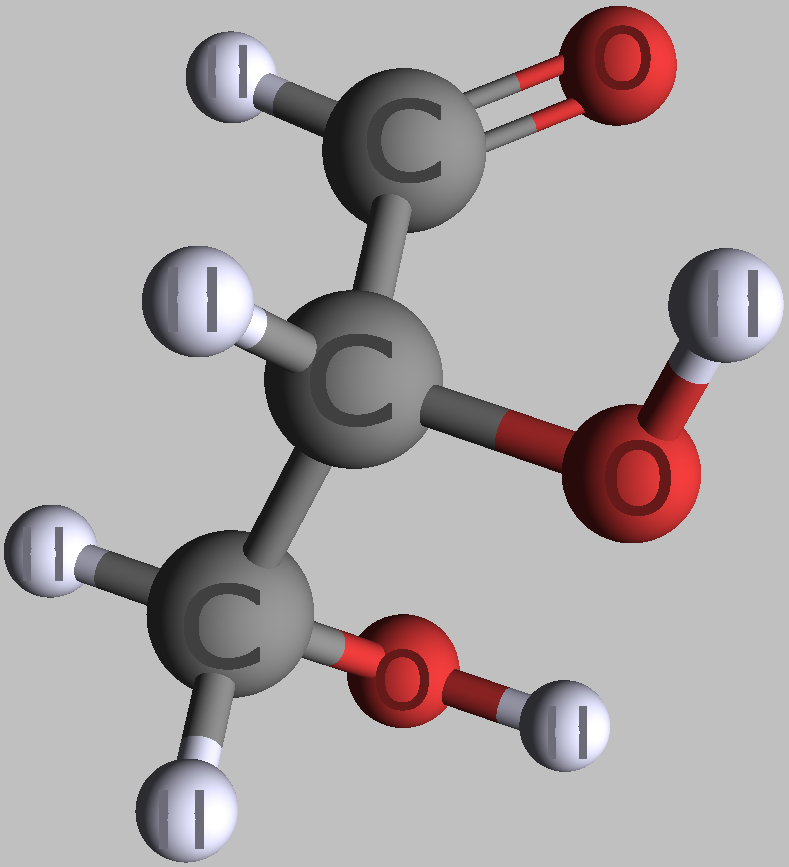 |
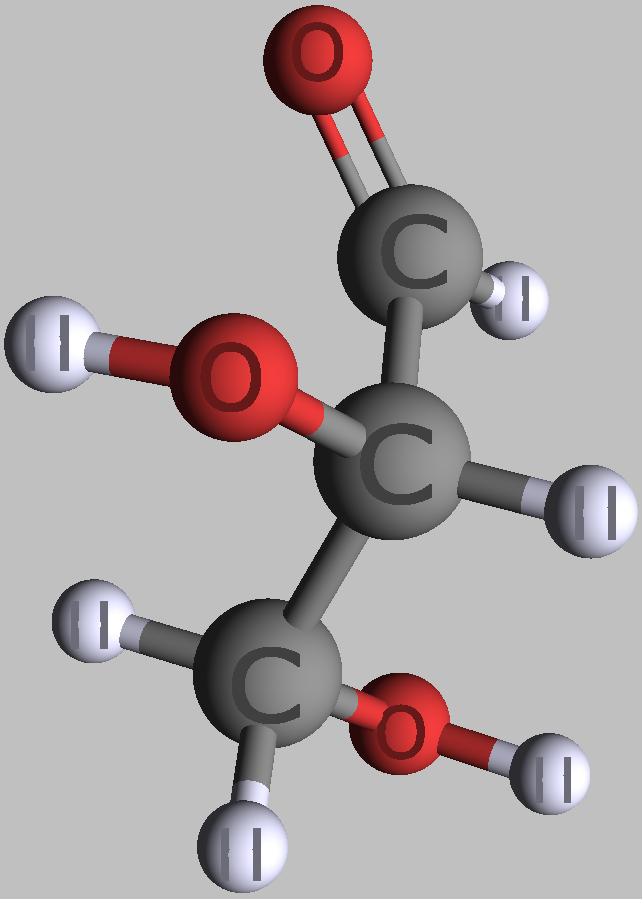 |
| D-Glycerinaldehyd | L-Glycerinaldehyd |
| Roland Heynkes, CC BY-SA 3.0. Die Koordinaten der Atome und Bindungen in den Molekülen habe ich aus der kostenlos im Internet verfügbaren Datenbank PubChem heruntergeladen und mit dem ebenfalls kostenlosen Pc3D Molecule Viewer dargestellt. | |
Der durch keine Drehung auflösbare Unterschied besteht am mittleren Kohlenstoff-Atom, an dem die Hydroxylgruppe (-OH) und das Wasserstoffatom (-H) die Plätze getauscht haben. Die Carboxylgruppe ganz oben sieht zwar links und rechts ebenfalls unterschiedlich aus, aber dieser Unterschied ließe sich durch Drehen am obersten C-Atom aufheben. Auch das unterste C-Atom kann man beliebig drehen, ohne dass sich der Rest des Moleküls mitbewegt. Dreht man jedoch das mittlere C-Atom, dann werden die beiden anderen C-Atome unvermeidbar mitgedreht.
Es ist also unwichtig, ob man die Sauerstoff-Atome der Carboxylgruppe oben und der Hydroxylgruppe am untersten C-Atom auf die linke oder rechte Seite schreibt. Man stellt deshalb die Atome einfach oben als CHO und unten als CH2OH dar. Nur am mittleren C-Atom ist es entscheidend, ob die Hydroxylgruppe links-vorne oder rechts-vorne steht. Vereinfacht kann man das einfachste Kohlenhydrat Glycerinaldehyd daher folgendermaßen darstellen:
| vereinfachte Darstellung von D-Glycerinaldehyd und L-Glycerinaldehyd | |
|---|---|
 |
|
| Roland Heynkes, CC BY-SA-4.0 | |
Auf einer eigenen Seite kann man sich mittels dreier selbst manipulierbarer, dreidimensionaler JSmol-Darstellungen die Strukturen der Zucker Alpha-D-Glucose, D-Fructose und Beta-D-Ribose von allen Seiten ansehen und diese Monosaccharid-Moleküle dadurch besser verstehen.

|
| Roland Heynkes, CC BY-SA 3.0 |
Zucker im biologischen Sinne sind alle süß schmeckenden Mono- und Disaccharide. Im Lebensmittelhandel meint man mit Zucker aber nur ein Disaccharid mit dem wissenschaftlichen Namen Saccharose. Wurde die Saccharose aus Zuckerrohr gewonnen, dann nennt man sie auch Rohrzucker. Wurde die Saccharose aus Zuckerrüben gewonnen, dann nennt man sie auch Rübenzucker. Bei anderen wichtigen Zuckern wie Traubenzucker (D-Glucose) und Milchzucker (Lactose) steckt im deutschen Namen ebenfalls eine Herkunftbezeichnung. Zucker schmeckt man in Süßigkeiten, Kuchen, Limonade sowie Obst. Von verstecktem Zucker spricht man, wenn man ihn in Nahrungsmitteln wie Ketchup und Fruchtjoghurt nicht vermutet und nicht deutlich schmeckt.
Zu den Kohlenhydraten gehören alle Zucker sowie zusätzlich die Oligosaccharide und Polysaccharide. Polysaccharide wie Zellulose oder Stärke schmecken nicht süß und sind deshalb keine Zucker. Trotzdem werden sie Vielfachzucker genannt, weil sie aus vielen Einfachzuckern (Monosacchariden) bestehen. Die sich im Polymer vielfach wiederholende Grundeinheit (Monomer) kann ein Monosaccharid oder ein Disaccharid (Zweifachzucker) sein. Für uns verdaubare Polysaccharide wie die Stärke gehören zu unseren Makronährstoffen. Für Zucker gilt das nicht, weil Zucker-Moleküle zu klein sind. Es ist zwar nicht üblich, aber man könnte sie zu den Mikronährstoffen zählen.
Das als Hauptbestandteil pflanzlicher Zellwände häufigste Polysaccharid ist die Zellulose. Für die meisten Menschen ist sie praktisch "nur" ein Ballaststoff, weil menschliche Zellen keine Enzyme zur Spaltung von Zellulose herstellen können. In den Dickdärmen mancher Menschen leben allerdings besonders viele Bakterien, die Zellulose zerlegen und dabei Fettsäuren produzieren. Einen Teil der Fettsäuren überlassen diese Bakterien ihren Menschen, die auf diese Weise Zellulose in nennenswertem Umfang als Nährstoff nutzen können. Ballaststoffe sind aber für die Gesundheit aller Menschen unverzichtbar, weil sie den Darm schützen und dessen Mikrobiom regulieren.
| Diese Abbildung zeigt Strukturformeln von Zellulose links und Stärke rechts | |
|---|---|
 |
 |
| Beide Zeichnungen wurden von einem anonymen Neurowissenschaftler unter der Lizenz Public domain veröffentlicht. | |
Für Menschen mit hohem Energiebedarf sind Kohlenhydrate wichtige und nützliche Nährstoffe. Man sollte allerdings normalerweise nicht zu viele Mono- und Disaccharide wie Traubenzucker, Fruchtzucker oder Rübenzucker essen und trinken, weil sie die Blutzuckerspiegel schneller und stärker ansteigen ansteigen lassen, als es gut für unsere Blutgfäße ist. Das Monosaccharid Traubenzucker (Glucose) gelangt innerhalb weniger Minuten durch die Mundschleimhaut ins Blut und liefert vor allem dem Gehirn fast sofort frische Energie. Ohne Nachschub ist die Glucose aber auch ähnlich schnell verbraucht. Außerdem reagiert die Bauchspeicheldrüse auf einen plötzlichen Anstieg der Glucose-Konzentration im Blut mit einer kräftigen Ausschüttuung des Hormons Insulin. Insulin veranlasst Leber- und Muskelzellen zu einer raschen Aufnahme von Glucose aus dem Blut. Deshalb hat das Gehirn nur sehr kurze Zeit etwas von dem aufgenommenen Traubenzucker. Immer mehr Wissenschaftler halten Zucker für gefährliche Gifte und mitverantwortlich für Zivilisationskrankheiten, die sehr viele Menschenleben kosten.
Stärke ist vor allem in pflanzlichen Nahrungsmitteln wie Brot, Nudeln, Reis und Kartoffeln, aber auch in Gemüse enthalten. Gegenüber Zuckern hat Stärke den Vorteil, seine Monomere weniger plötzlich und dafür anhaltender verfügbar zu machen und den Zähnen weniger zu schaden. Denn sie muss erst noch verdaut werden. Dadurch steigt der Blutzuckerspiegel über mindestens 1 Stunde langsam an, bleibt etwa 1 Stunde im Gleichgewicht und sinkt dann rund 1 Stunde lang wieder ab. Obwohl wir vollkommen ohne Kohlenhydrate leben könnten, ist deshalb die Aufnahme von Stärke sehr nützlich, wenn man sich auf eine große und lange andauernde körperliche (Ausdauersport) oder geistige (z.B. Klassenarbeit) Anstrengung vorbereitet.
Natürlich hängt die Zucker-Konzentration in unserem Blut nicht nur von unserer aktuellen Ernährung ab. Überschüssige Glucose wird von Muskel-, Nieren- und Leberzellen in das verzweigte Polysaccharid Glykogen umgewandelt und im Cytoplasma gespeichert. Bei Bedarf können sie aus ihren Glycogen-Speichern wieder Glucose freisetzen. Während Muskeln und Nieren ihr Glykogen selbst brauchen, speichert die Leber vor allem für das Gehirn, das sich fast nur von Zucker ernährt und ein Fünftel unserer Energie verbraucht.
| D-Glucose in verschiedenen Formen und Darstellungen | ||
|---|---|---|
| D-Glucose ist das Monosaccharid (Einfachzucker) Traubenzucker mit 6 C-Atomen und der Summenformel C6H12O6. L-Glucose spielt in Lebewesen keine Rolle. D-Glucose ist ein Monomer (Baustein) zahlreicher pflanzlicher Polysaccharide und tierischer Glykoproteine. Die D-Glucose kann verschiedene Konfigurationen annehmen, für die es verschiedene Schreibweisen gibt. | ||
| Keilstrichformel | Haworth-Schreibweise | |
 D-Glucose |
 alpha-D-Glucofuranose |
 β-D-Glucofuranose |
 α-D-Glucopyranose |
 β-D-Glucopyranose |
|
| NEUROtiker, gemeinfrei | ||
 |
Das Schema links zeigt die reversible Umwandlung der Alpha- in die Beta-Konfiguration der Glucose. | |
| anonym, Public domain | ||
 | ||
| 1. Tollens-, 2. Haworth-, 3. Sesse-l und 4. absolut-stereochemische Darstellung von alpha-D-Glucopyranose | ||
| anonym, Public domain | ||
|
 Diese kleine Animation eines anonymen Zeichners zeigt den Ringschluss eines β-D-Glucopyranose-Moleküls |
|
Die meisten Kinder bevorzugen süße Speisen. Sie vermissen aber nichts und entwickeln später auch keine suchtähnliche Vorliebe für Süßigkeiten, wenn kleinen Kindern keine Süßigkeiten angeboten werden. Süßigkeiten enthalten zwar viel chemische Energie, aber meistens kaum Vitamine, Mineralstoffe und Ballaststoffe. Außerdem werden die meisten Menschen von Süßigkeiten und stark gesüßten Getränken dick. Ständiger Genuss von Süßigkeiten zwingt den Körper zu einer ständigen Produktion größerer Mengen des Hormons Insulin und hemmt gleichzeitig die Produktion des Schlafhormons Melatonin. Über Jahre kann dazu führen, dass sich Zellen des Körpers an das Insulin zu sehr gewöhnen und immer weniger darauf reagieren. So entwickelt man langsam den gefährlichen Typ-2-Diabetes. Krebszellen lieben und brauchen Glucose. Besonders ungesund ist Fruchtzucker (Fructose), der etwas süßer und billiger als Glucose ist ud deshalb gerne von der Nahrungsmittel- und Getränke-Industrie benutzt wird.
Sehr kompliziert aufgebaute Kohlenhydrate entstehen im endoplasmatisches Retikulum ER und im Golgi-Apparat auf den Oberflächen von Membranproteinen. Sie erfüllen später verschiedene Aufgaben auf der äußeren Oberfläche der Zellmembran. Aber unsere Zellen stellen diese Kohlenhydrate vollständig selbst her und benötigen dafür keine Monomere aus der Nahrung. Die Kohlenhydrate in unserer Nahrung benötigen wir deshalb nicht als Baustoffe, sondern nur als Ballaststoffe und für unsere Versorgung mit chemischer Energie.
| Aufgabe zur Erarbeitung des Lerntextes bzw. zur Lernkontrolle | |
|---|---|
| 13 | Beschreibe den generellen Aufbau einer Aminosäure! |
| Hier geht es zur Antwort. | |
Auf der Grundlage der von PubChem kostenlos im Internet zur Verfügung gestellten Koordinaten der Atome und Atombindungen der kleinsten Aminosäure Glycin und mit Hilfe der dreidimensionalen Darstellung durch den ebenfalls kostenlosen Pc3D Molecule Viewer verdeutlicht die folgende Grafik den generellen Aufbau einer Aminosäure. Man erkennt Aminosäuren daran, dass sie am zentralen C-Atom neben einem Wasserstoffatom eine leicht basische Aminogruppe und eine leicht saure Carboxylgruppe besitzen. Der mit R nur angedeutete Rest ist bei jeder der 21 unterschiedlichen Aminosäuren menschlicher Proteine ein anderer.

|
Die folgende Übersicht zeigt 20 der 21 Aminosäuren, aus denen unsere Eiweiße aufgebaut sind. Um funktionelle Gruppen und besondere Atome hervorzuheben, fehlen in dieser Darstellung die Kohlenstoff- und Wasserstoffatome der Grundgerüste. Diese Übersicht soll vor allem zeigen, dass die verschiedenen Aminosäuren recht unterschiedliche Eigenschaften haben. Es gibt saure, basische und neutrale Aminosäuren sowie polare und unpolare oder hydrophile und hydrophobe.
| die 20 normal codierten Aminosäuren menschlicher Proteine |
|---|
 |
| anonym, public domain |
Wie es schon ihr Name verrät, sieht man in den aus Proteinen bekannten Alpha-L-Aminosäuren eine leicht basische Aminogruppe und am selben C-Atom hängend eine leicht saure Carboxylgruppe. Außerdem mit diesem zentralen C-Atom verbunden sind ein Wasserstoffatom und ein Rest, der sich bei verschiedenen Aminosäuren unterscheidet. In Proteinen ist immer eine Aminogruppe einer Aminosäure mit einer Carboxylgruppe der benachbarten Aminosäure verbunden.
| zwei einfache Alpha-L-Aminosäuren | |
|---|---|
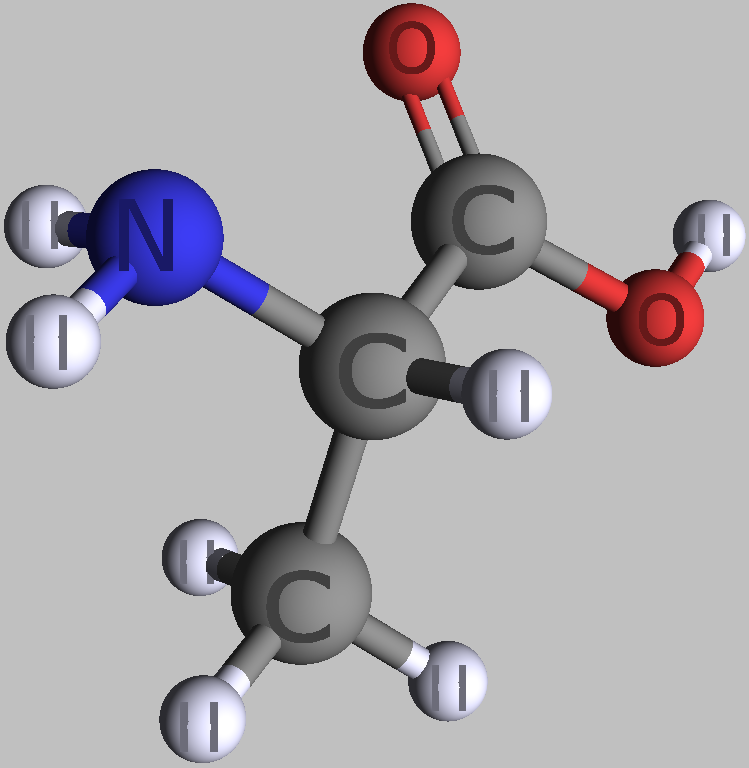 |
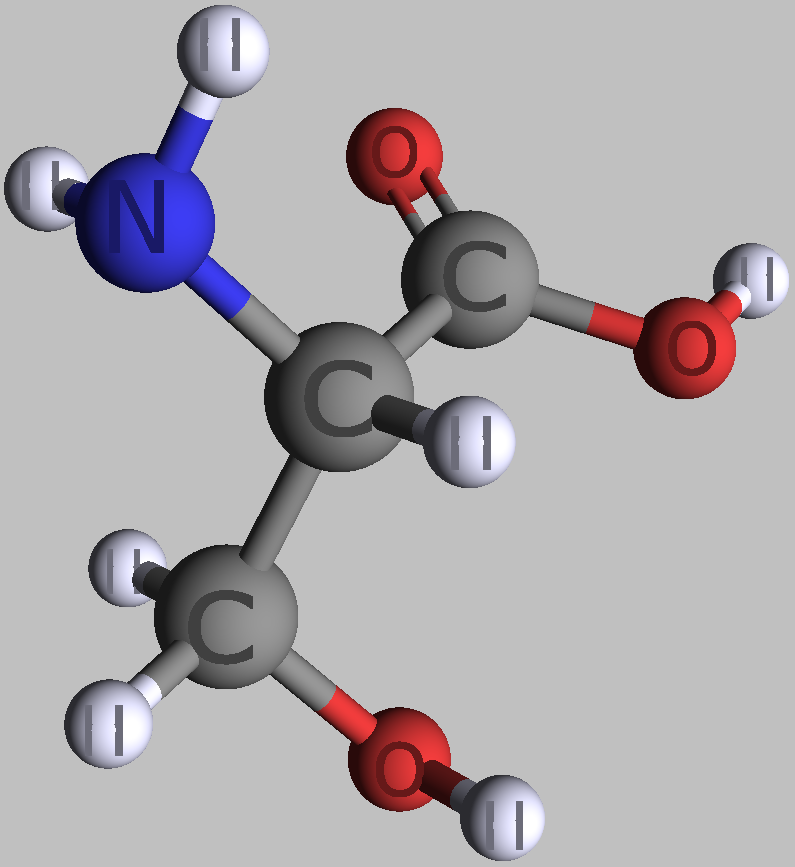 |
| L-Alanin | L-Serin |
| Roland Heynkes, CC BY-SA-4.0 | |
Auf einer eigenen Seite kann man sich mittels dreier selbst manipulierbarer, dreidimensionaler JSmol-Darstellungen die Strukturen der Aminosäuren L-Asparaginsäure, L-Histidin und L-Tryptophan von allen Seiten ansehen und diese Aminosäure-Moleküle dadurch besser verstehen.
| Aufgabe zur Erarbeitung des Lerntextes bzw. zur Lernkontrolle | |
|---|---|
| 14 | Definiere (Erkläre, unterscheide) die Begriffe Peptid, Dipeptid, Oligopeptid, Polypeptid und Protein! |
| Hier geht es zur Antwort. | |
Peptid nennt man eine unverzweigte organisch-chemische Verbindung von mindestens zwei Aminosäuren, wobei die Aminosäuren durch Peptidbindung miteinander verbunden sind. Ein Peptid aus zwei Aminosäuren heißt Dipeptid. Sind es mehrere Aminosäuren, dann heißt das Peptid auch Oligopeptid. Sind es viele Aminosäuren, dann heißt ein Peptid auch Polypeptid. Hat ein unverzweigtes Polypeptid eine Funktion, dann nennt man es Protein.
| Peptidbindung | |
 | |
|
Peptidbindung heißt eine Amid-Bindung, wenn sie zwei Aminosäuren verbindet. Das Bild oben zeigt jeweils links und rechts die mesomeren Grenzstrukturen der häufigeren trans- sowie der selteneren cis-Konfiguration eines Dipeptids aus zwei Alanin-Molekülen. Die tatsächliche Verteilung der Elektronen in dieser Amid-Bindung entspricht einer Mischung aus den beiden mesomeren Grenzstrukturen. Die Mesomerie der Amid/Peptidbindung bewirkt, dass Peptidbindungen starr und planar sind. Das bedeutet, dass sich alle Atome der Peptidbindung in einer Ebene befinden und dass eine Drehung um die Bindung zwischen dem Stickstoff- und dem Kohlenstoff-Atom nicht möglich ist, weil diese Bindung teilweise den Charakter einer Doppelbindung hat. Deshalb kann die trans-Konfiguration nicht einfach in die cis-Konfiguration übergehen. Die blau dargestellten Atome und Bindungselektronenpaare liegen alle in einer Ebene. Das folgende Schema deutet ohne Reaktionsmechanismus die Kondensations-Reaktion an, die unter Abspaltung eines Wasser-Moleküls zwei Aminosäuren (Alanine) zu einem Peptid (Dipeptid) verknüpft. | |
 | |
| Renate90, CC BY-SA 3.0 | |
| Das folgende Schema deutet den Reaktionsmechanismus der Hydrolyse einer Peptid-Bindung an. | |
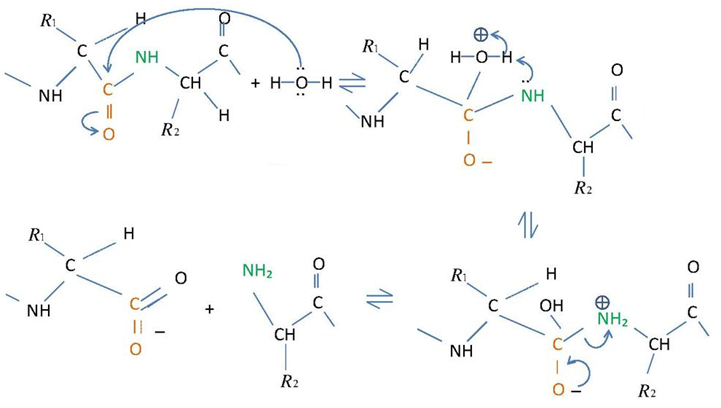 | |
| Xrajvinder, CC BY-SA 3.0 | |
Proteine sind lange, unverzweigte Ketten aus Aminosäuren, von denen es in unseren Zellen 21 unterschiedliche gibt. Diese Aminosäureketten falten sich in Abhängigkeit von der Reihenfolge (Sequenz) der Aminosäuren. Dabei unterscheidet man 4 Struktur-Ebenen:
| Das schrittweise Entstehen der räumlichen Form eines Proteins |
|---|
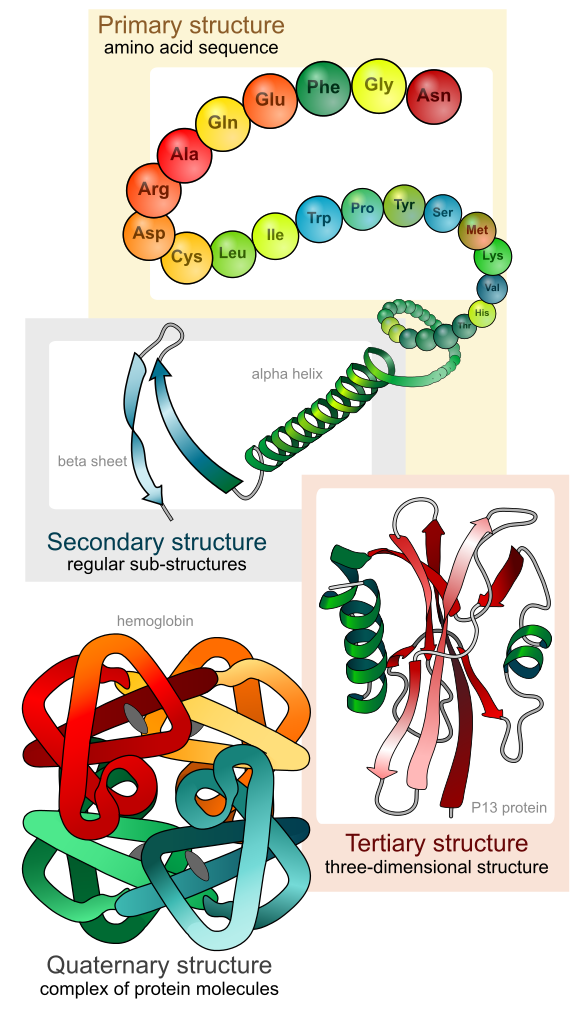
|
| Mariana Ruiz Villarreal, Beschriftung von mir, public domain |
| So ergibt sich aus der Aminosäuresequenz die räumliche Form eines Proteins. Die Form bestimmt die Eigenschaften und damit auch die Funktionen eines Proteins. Und die Funktionen unserer Proteine bestimmen unsere Eigenschaften. |
| rotierendes Protein (Clostridium perfringens Alpha Toxin) |
|---|
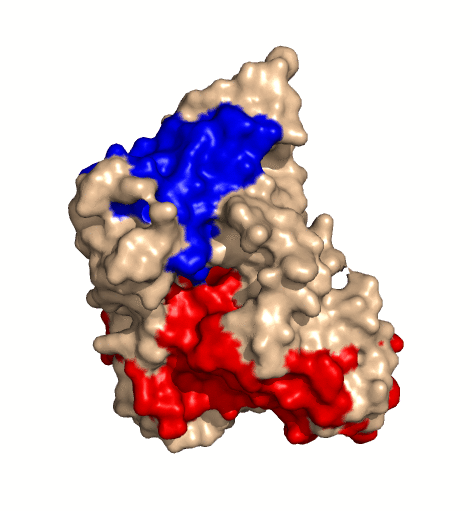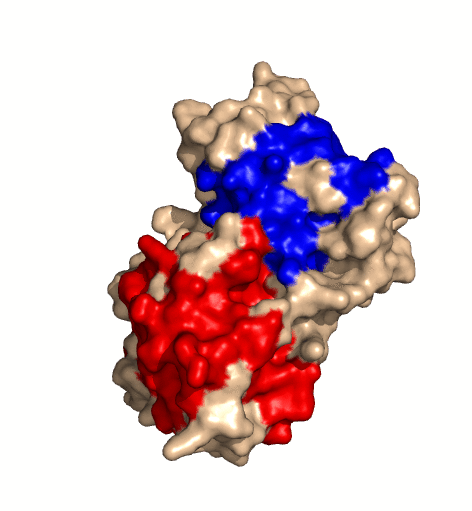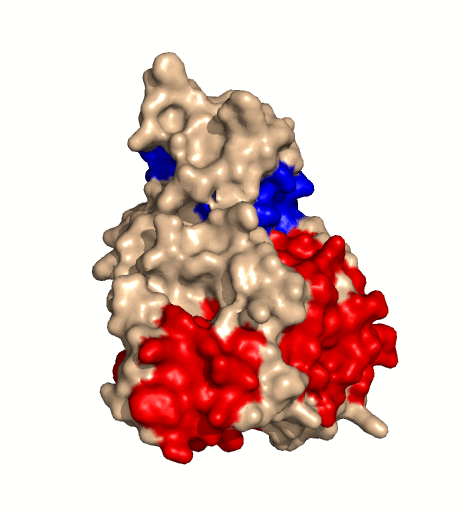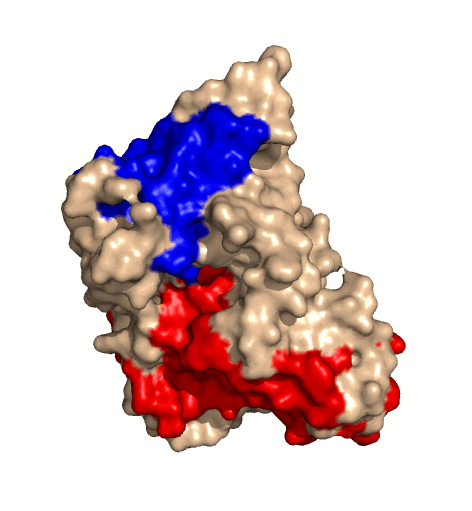 |
| Ramin Herati, public domain |
Das Problem dabei ist, dass es nahezu unendlich viele mögliche Reihenfolgen (Sequenzen) gibt, wenn Hunderte Aminosäuren ein Protein bilden und für jede Position der Aminosäure-Sequenz 21 unterschiedliche Aminosäuren zur Auswahl stehen. Damit eine Zelle von den praktisch unendlich vielen möglichen immer genau die richtige Aminosäurekette produziert, braucht sie für jedes seiner Proteine einen Bauplan. Solch einen Bauplan nennt man Gen. Es gibt im Prinzip für jedes Protein ein Gen, welches die Aminosäuresequenz des Proteins bestimmt. Und die Summe aller Gene nennt man das Genom eines Lebewesens.
| rotierendes Protein (AMPA-Rezeptor) |
|---|
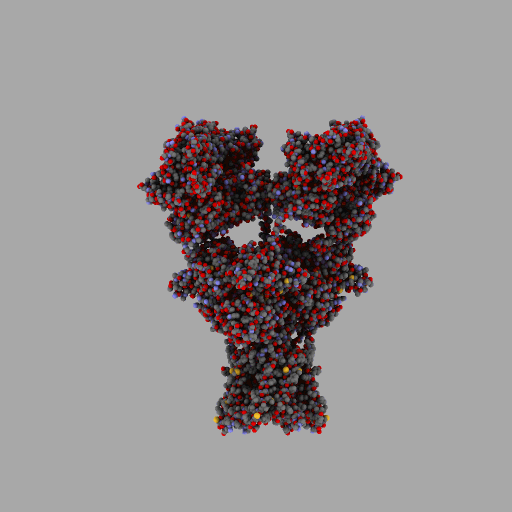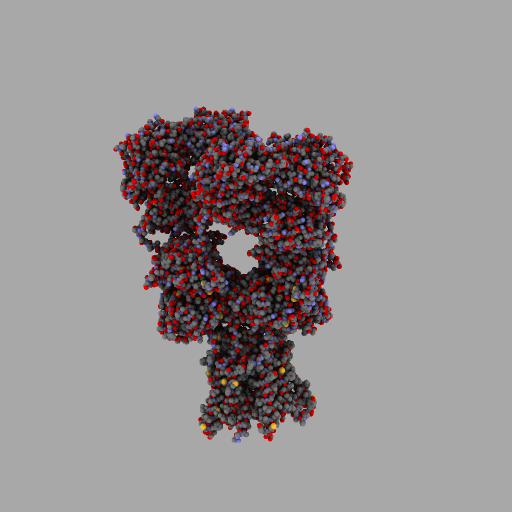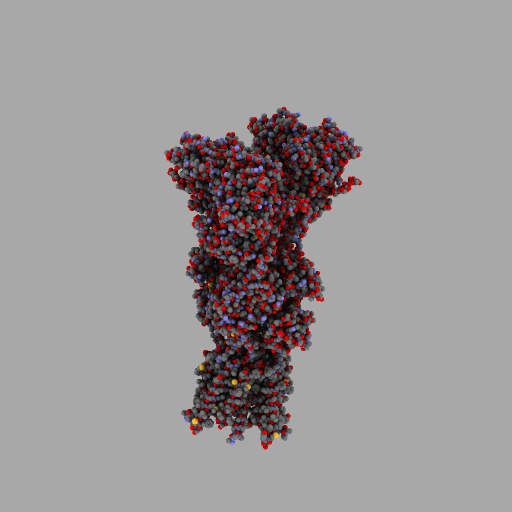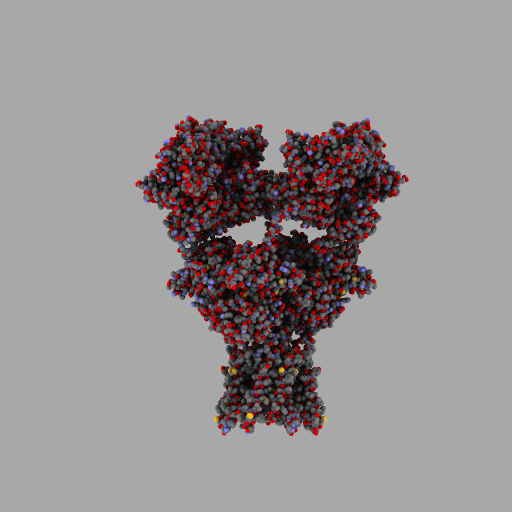 |
| anonym, CC BY-SA 3.0 |
Entscheidend für die Eigenschaften jedes Lebewesens und jede seiner Zellen ist also, wann, für wie lange und wie stark seine Gene aktiviert werden und welche Aminosäuresequenzen sie codieren.
Eine häufige Sekundärstruktur innerhalb von Proteinen ist die Alphahelix. Gut erkennbar wird sie allerdings erst, wenn man nur das Grundgerüst der Kette von Peptidbindungen betrachtet.
| Schemata einer Alphahelix (2L91) | |
|---|---|
 |
Das Bild zeigt zwei Darstellungen des selben Peptids, dessen Aminosäuren eine Alphahelix bilden. Links sieht man nur das Rückrat aus Peptidbindungen. Rechts sieht man jedes Atom. |
| Roland Heynkes, CC BY-SA-4.0 (Anklicken des Bildes führt zu einem 3D-Modell.) | |
Eine Alphahelix kann sich formen, wenn in einem Peptid oder Protein bestimmte Aminosäuren aufeinander folgen. Der Grund dafür ist, dass die Alphahelix durch bestimmte Wasserstoffbrückenbindungen stabilisiert wird.
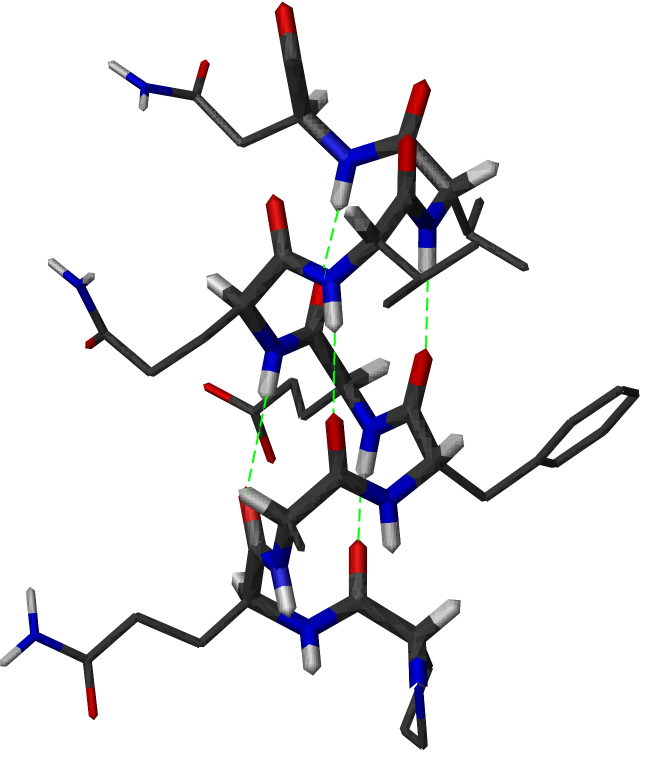
Die folgende Zeichnung ermöglicht eine ruhige Betrachtung aller chemischen Bindungen innerhalb einer Alphahelix einschließlich der vollständigen Aminosäuren. Dabei erscheinen die Bindungselektronen der Kohlenstoff-Atome grau, die der Sauerstoff-Atome rot und die der Stickstoff-Atome blau. Die Atome selbst sind nicht zu sehen, aber das dient der Übersichtlichkeit.
|
Das Schema zeigt Wasserstoffbrückenbindungen innerhalb einer Alphahelix.
|
|
| Frédéric Dardel, CC BY-SA 3.0 |
Das folgende Schema erleichtert durch die Drehung ein räumliches Verständnis der Alphahelix. Pink gezeichnet sind die Wasserstoffbrückenbindungen zwischen freien Elektronenpaaren partiell negativ geladener Sauerstoff-Atome und an etwas weniger elektronegative Stickstoff-Atome gebundenen Wasserstoffatomen.
|
Das rotierende Schema zeigt die Wasserstoffbrückenbindungen innerhalb einer Alphahelix.
|
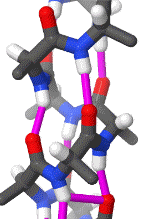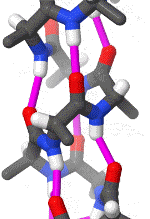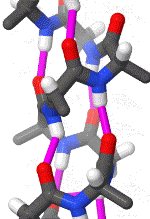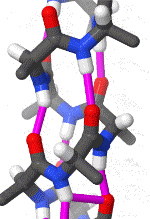
|
| Karsten Theis, CC BY-SA 4.0 |
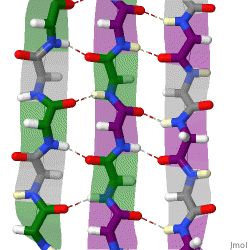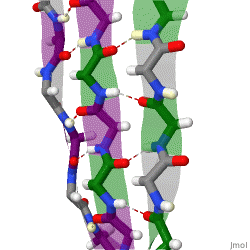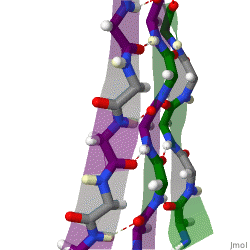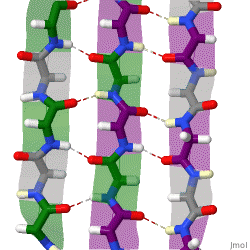
Während die Alphahelix durch interne Wasserstoffbrückenbindungen stabilisiert wird, wirken stabilisierende Wasserstoffbrückenbindungen zwischen benachbarten Beta-Faltblättern.
|
Das rotierende Schema zeigt drei Beta-Faltblätter, die sich gegenseitig durch Wasserstoffbrückenbindungen stabilisieren.
|
|
| Karsten Theis, CC BY-SA 4.0 |
Benachbarte und sich gegenseitig stablisierende Beta-Faltblätter können parallel oder antiparallel ausgerichtet sein.
| Die beiden Schemata zeigt jeweils zwei Beta-Faltblätter, die sich gegenseitig durch Wasserstoffbrückenbindungen stabilisieren. | |
 |
 |
| parallel, anonym, public domain | antiparallel, anonym, public domain |
Nutzt man zur Darstellung eines ß-Faltblattes experimentell ermittelte reale Koordinaten, dann ist das ß-Faltblatt schwer zu erkennen.
| die räumliche Anordnung aller Atome eines ß-Faltblattes | |
|---|---|
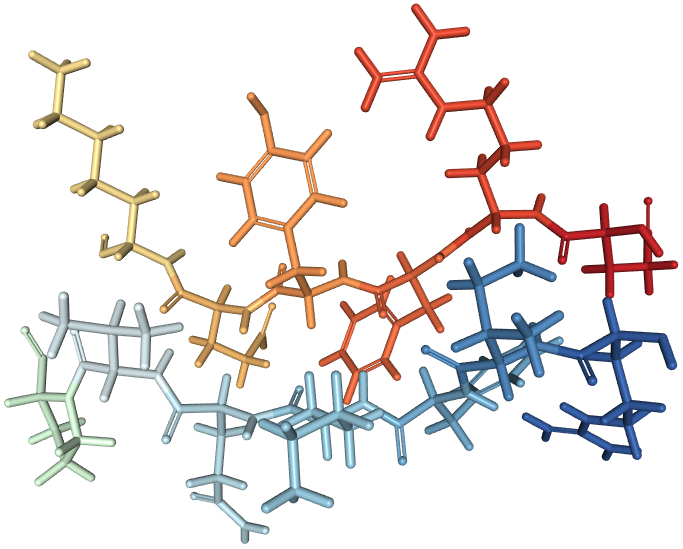 |
In dieser Licorice genannten Darstellung sieht man zugunsten möglichst großer Übersichtlichkeit nur die Atombindungen. |
| Protein Data Bank ID: 2N6H, public domain | |
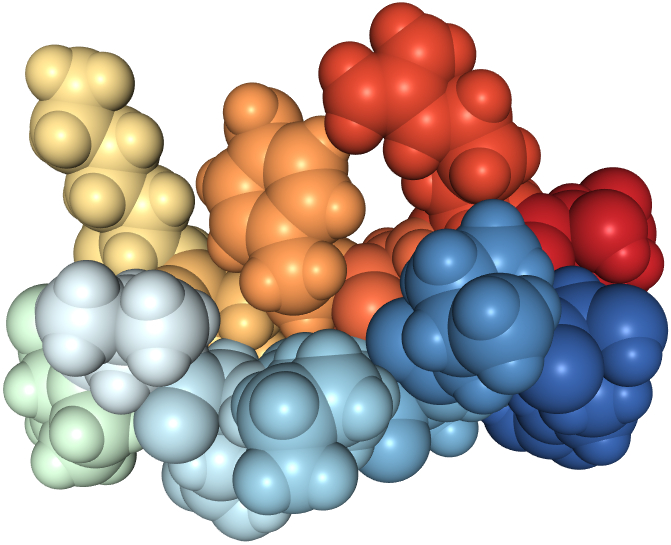 |
Diese Spacefill genannte Darstellung zeigt, welchen Platz jedes einzelne Atom einnimmt. |
| Die beiden Grafiken zeigen das selbe ß-Faltblatt. Auf einer eigenen Seite kann man sich mittels dreier selbst manipulierbarer, dreidimensionaler JSmol-Darstellungen die Struktur des ß-Faltblattes erforschen. | |
| Aufgaben zur Erarbeitung dieses Kapitels bzw. zur Lernkontrolle | |
|---|---|
| 15 | Erkläre, warum die Reihenfolge der Aminosäuren in einem Protein so entscheidend wichtig ist! |
| 16 | Erkläre, warum wir Proteine essen müssen! |
| Hier geht es zu den Antworten. | |
Proteine oder Eiweiße heißen die Biomoleküle, aus denen die meisten unserer Enzyme bestehen. Andere Proteine leisten die Arbeit in unseren Zellen oder machen die Haare und Knochen zugfest. Proteine (Eiweiße) sind relativ große Moleküle (aus mehr als 1000 Atomen) und zählen deshalb zu den Makromolekülen. Sie sind so groß, weil Proteine unverzeigte Polymere (poly = viele) aus vielen Aminosäuren (den Monomeren, mono = 1) sind. Die Aminosäuren sind wie die Perlen einer Perlenkette aneinander gereiht. Anders als eine Halskette sind die Aminosäureketten allerdings meistens eng zusammen geknäuelt. Dabei hängen die Form (Struktur) und die Funktion eines Eiweißes von der Reihenfolge (Sequenz) der Aminosäuren in der Kette ab. Denn die Sequenz der Aminosäuren bestimmt, wie sich die Kette (das Protein) zusammenfaltet. Einen Überblick über die vielfältigen Formen der Proteine bietet ein Poster der Protein Data Bank, in das man tief hinein zoomen kann.
Lernkasten Proteine
|
| Hühner-Eiweiß-Lysozym | |
|---|---|
 |
Links sieht man das kleine Enzym Lysozym aus Hühner-Eiweiß. Das von mir mit dem Java-Programm JMol und den hochauflösenden Daten 2VB1 der Protein Data Bank erzeugte Bild zeigt, wie sich die Kette von 129 (zur besseren Unterscheidung) unterschiedlich gefärbten Aminosäuren relativ dicht zusammen ballt. |
| Roland Heynkes, CC BY-SA-4.0 | |
Besonders viel tierisches Eiweiß enthalten Muskeln, Haare, Fuß- und Fingernägel bzw. Krallen und Hufe, aber wir essen natürlich nur das Fleisch von Säugetieren, Geflügel und Fisch. Rindfleisch und viele Fischarten sollten nicht im Übermaß konsumiert werden, weil die in ihnen reichlich vorhandenen Purine schmerzhafte Gichtanfälle verursachen können. Eier und Milchprodukte sind tierische Nahrungsmittel mit ebenfalls hohem Protein-Gehalt. Vollkornprodukte sowie Hülsenfrüchte wie Bohnen, Linsen, Erbsen, Sojabohnen oder Erdnüssen sind die pflanzlichen Nahrungsmittel, mit denen wir großenteils unseren Eiweißbedarf decken.
Einige Aminosäuren können unsere Zellen nicht selbst herstellen. Da wir sie aber unbedingt brauchen, nennt man sie die essenziellen Aminosäuren. Um uns mit essenziellen Aminosäuren zu versorgen, müssen wir mit tierischen oder pflanzlichen Nahrungsmitteln Proteine aufnehmen und verdauen. Die Aminosäuren werden aus dem Dünndarm ins Blut aufgenommen und zu den Zellen transportiert, die daraus unsere eigenen Proteine aufbauen.
Das in der Hypophyse gebildete Follikel-stimulierende-Hormon ist ziemlich groß und und komplex aufgebaut.
| Schema des aus zwei Peptiden bestehenden Follikel-stimulierenden Proteins (1FL7) |
|---|
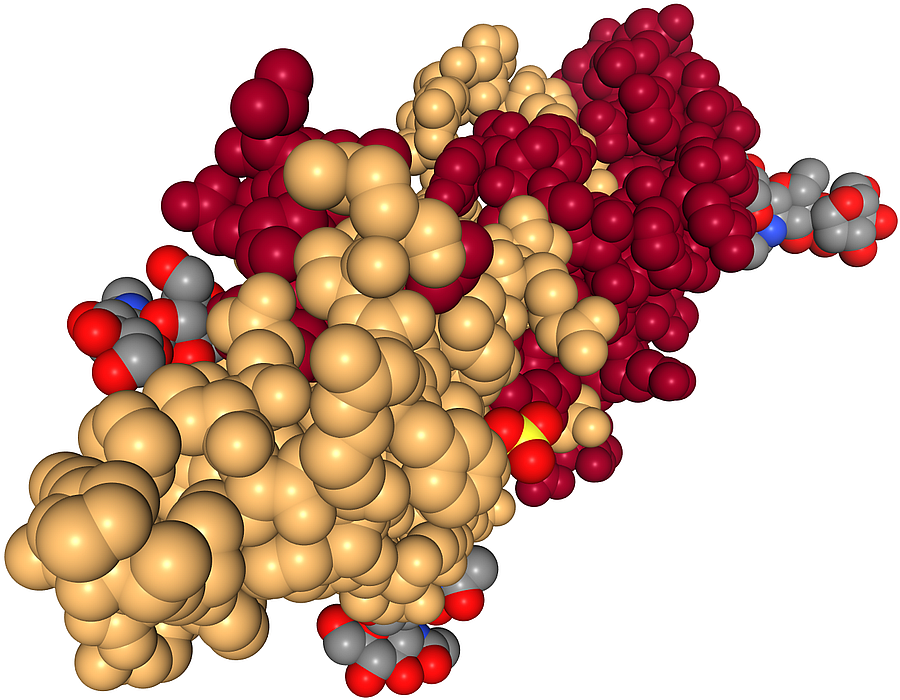 |
| Roland Heynkes, CC BY-SA-4.0 (Anklicken des Bildes führt zu einem 3D-Modell.) |
| Das Bild zeigt das aus zwei großen Peptiden oder kleinen Proteinen bestehende Follikel-stimulierende Protein des Menschen. Die aus 92 Aminosäuren bestehende rote Kette ist die alpha-Untereinheit, die hellbraune Kette aus 111 Aminosäuren stellt die beta-Untereinheit dar. Außerdem sieht man als Liganden Phosphorsäure mit gelbem Phosphor und roten Sauerstoff-Atomen sowie drei Kohlenhydrat-Liganden mit grauen Kohlenstoff-Atomen. Die auf Chromosom 6 codierte alpha-Untereinheit ist auch Bestandteil der Hormone hCG (humanes Choriongonadotropin), LH (luteinisierendes Hormon) und TSH (Thyreotropin), während die auf Chromosom 11 codierte beta-Untereinheit spezifisch für FSH ist. |
Die folgenden Schemata zeigen in verschiedenen Darstellungen der Protein-Struktur eine Protein-Disulfid-Isomerase des bekannten Darmbakteriums Escherichia coli. Grundlage dieser Darstellungen sind die mit der Nummer 1TJD in der RCSB Protein Data Bank (RCSB PDB) Interesierten kostenlos zur Verfügung gestellten Koordinaten der Atome dieses Proteins.
| Dieses Schema zeigt die Protein-Disulfid-Isomerase in der Darstellungsform Spacefill ByResidue. |
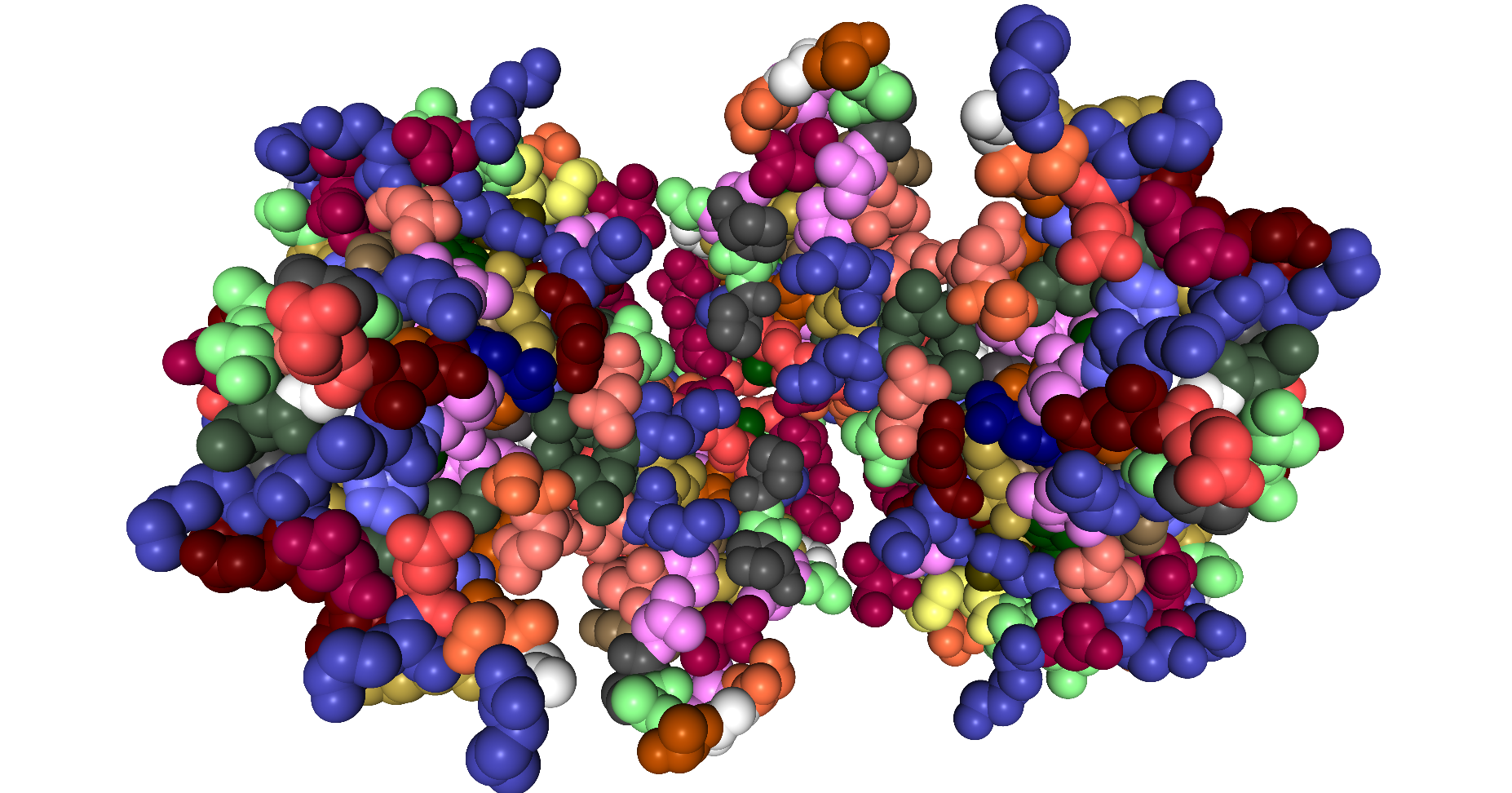
|
| Roland Heynkes mit Hilfe des Viewers NGL (WebGL) auf Internetseiten der RCSB Protein Data Bank (RCSB PDB), CC BY-SA-4.0 |
Diese Darstellung ist zwar schön bunt, weil jede Aminosäure in einer anderen Farbe dargestellt wird. Aber innere Strukturen sind so nicht erkennbar, denn man sieht nur eine Oberfläche.
Die folgende Darstellung im Format namens Litorice zeigt nur die Atombindungen der Kohlenstoff-Gerüste der Aminosäuren. Dadurch wird die ganze Struktur viel transparenter. So wird erkennbar, dass es sich um eine Quartärstruktur aus zwei Untereinheiten (Tertiärstrukturen) handelt.
| Dieses Schema zeigt die Protein-Disulfid-Isomerase in der Darstellungsform Backbone by Secondary Structure. |
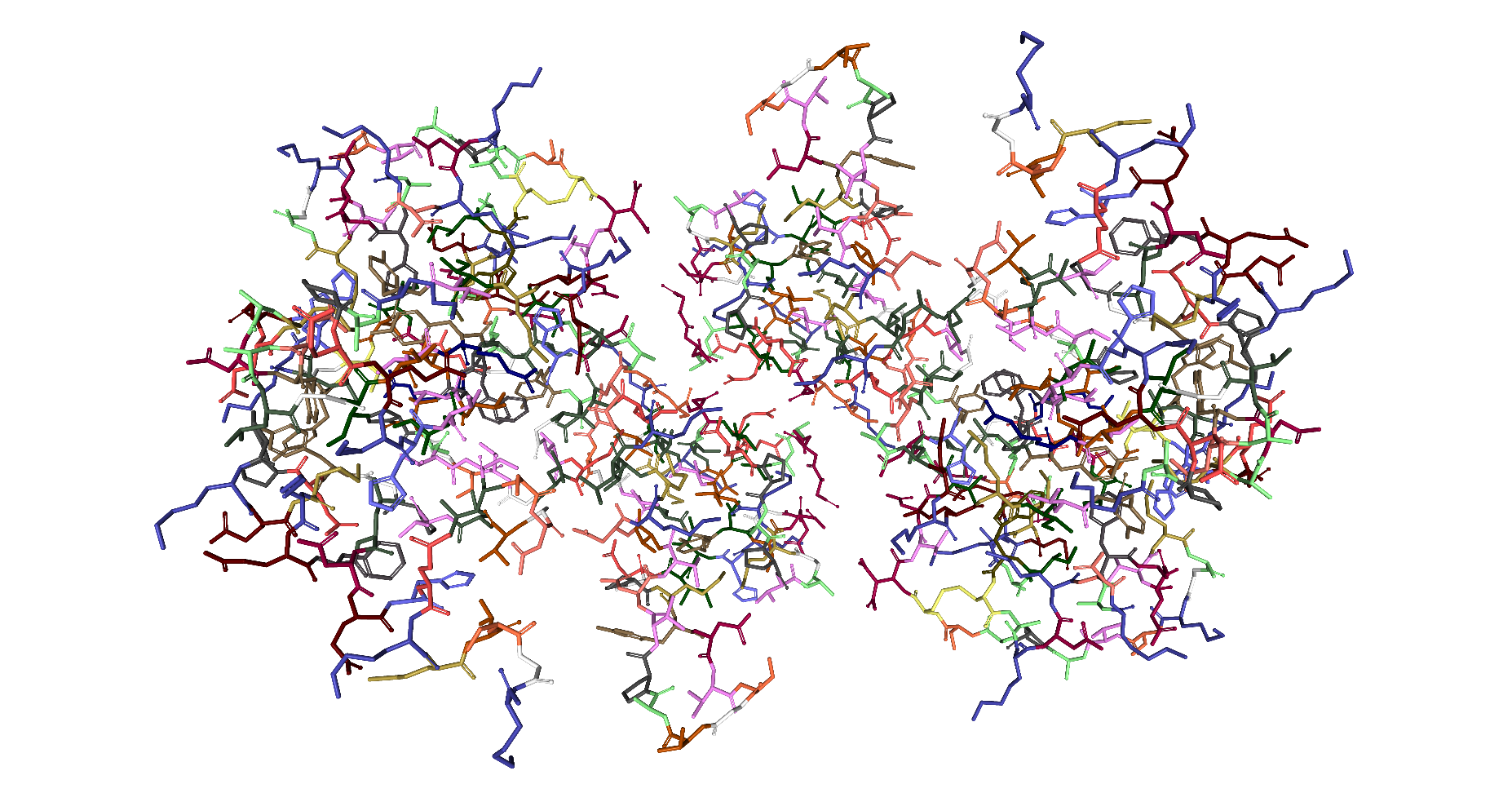
|
| Roland Heynkes mit Hilfe des Viewers NGL (WebGL) auf Internetseiten der RCSB Protein Data Bank (RCSB PDB), CC BY-SA-4.0 |
Will man auch die Sekundärstrukturen des Proteins sehen, dann muss man sich auf die Darstellung der Peptidbindungen ohne die unterschiedlichen Aminosäure-Reste beschränken.
| Dieses Schema zeigt die Protein-Disulfid-Isomerase in der Darstellungsform Backbone by Secondary Structure. |
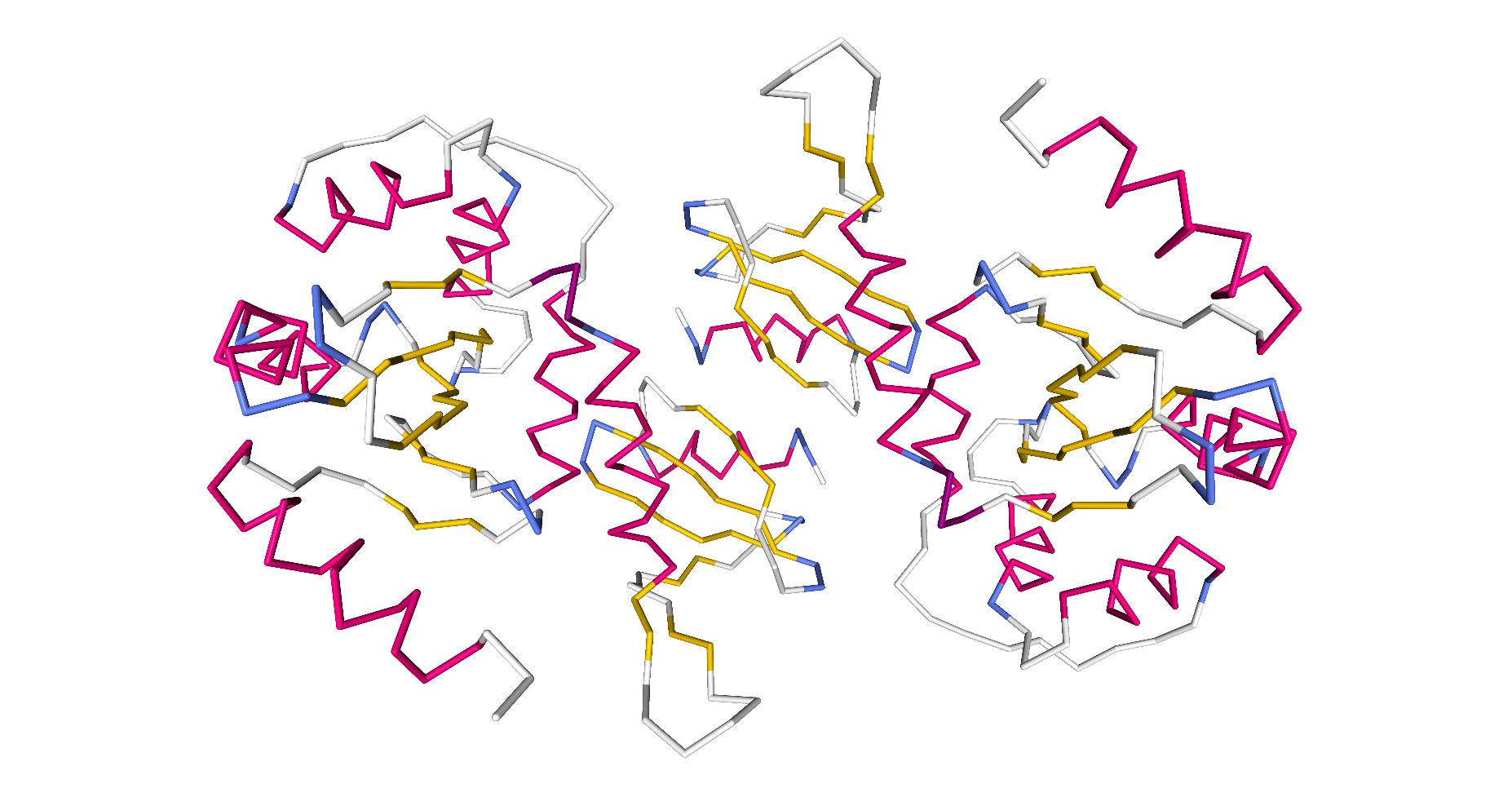
|
| Roland Heynkes mit Hilfe des Viewers NGL (WebGL) auf Internetseiten der RCSB Protein Data Bank (RCSB PDB), CC BY-SA-4.0 |
Obwohl die Sekundärstrukturen sogar farblich hervor gehoben sind, erkennt man sie doch nur schwer. Das wird erst leicht durch die folgende Darstellung. Rot sind die Alphahelices, gelb die ß-Faltblätter, blau die Turns und weiß die flexiblen Bereiche des Proteins.
| Dieses Schema zeigt die Protein-Disulfid-Isomerase in der Darstellungsform Cartoon by Secondary Structure. |
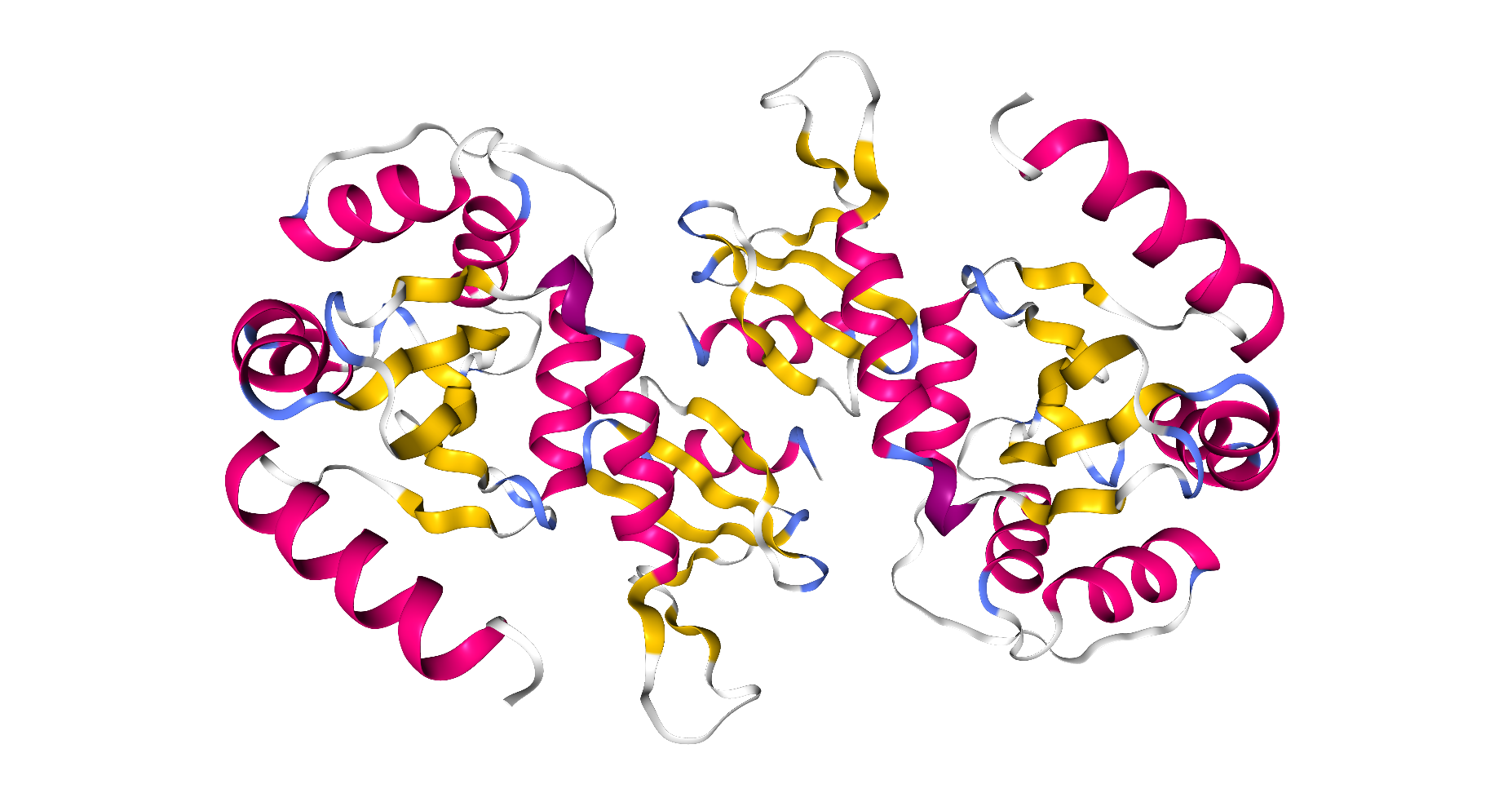
|
| Roland Heynkes mit Hilfe des Viewers NGL (WebGL) auf Internetseiten der RCSB Protein Data Bank (RCSB PDB), CC BY-SA-4.0 |
Nukleinsäuren (DNA oder RNA) sind das Material, aus dem die Baupläne aller Lebewesen bestehen. Nucleotide sind die Monomere der Nukleinsäuren und es gibt in DNA und RNA jeweils 4 verschiedene Sorten von Nucleotiden.
| Aufbau der Nucleotide |
|---|

|
| Yikrazuul und Roland Heynkes, CC BY-SA-4.0 |
| Ähnlich wie die Proteine und Polysaccharide bestehen auch die Nucleinsäuren (DNA und RNA) aus unzähligen Grundbausteinen, den Monomeren. Diese Monomere heißen bei den Proteinen Aminosäuren, bei Polysacchariden wie Stärke und Zellulose heißen sie Monosaccharide (Einfachzucker) und bei Nukleinsäuren nennt man sie Nucleotide. Die in den Nucleinsäuren eingebauten Nucleotide kann man auch Nukleosidmonophosphate nennen. Bevor sie in eine Nukleinsäure eingebaut werden, besitzen sie drei Phosphate und heißen Nukleosidtriphosphate. Die Abspaltung der beiden äußeren Phosphatreste liefert die Energie für den Einbau in die Nukleinsäure. Jedes Nucleotid besteht aus dem Einfachzucker Ribose (in RNA) oder Desoxyribose (in DNA), an dem ein Molekül Phosphorsäure sowie eine organische Base hängen. Von den Basen gibt es in der DNA 4 verschiedene: Adenin, Cytosin, Guanin und Thymin. Adenin, Cytosin und Guanin kommen auch in der RNA vor, aber Thymin ist dort durch Uracil ersetzt. |
Die Nukleotide entsprechen den Buchstaben unserer Schriftsprache. DNA und RNA enthalten jeweils 4 verschiedene Sorten von Nukleotiden:
RNA ist die international gebräuchliche Abkürzung für Ribonucleic Acid (deutsch: Ribonukleinsäure = RNS). Schon die Namen zeigen, dass die Unterschiede zwischen RNA und DNA gering sind, denn DNA ist die Abkürzung von Desoxyribonucleic Acid. Die Vorsilbe "Des" sagt, dass der DNA etwas fehlt. Das "oxy" sagt uns, was fehlt. Verglichen mit der RNA fehlt bei der DNA am Zucker-Molekül Ribose ein Sauerstoff-Atom. Ein weiterer Unterschied zwischen DNA und RNA besteht darin, dass die RNA statt Thymin die sehr ähnliche Nukleobase Uracil enthält.
Im Mai 1952 schickten die britische Biochemikerin und Spezialistin für die Röntgenstrukturanalyse kristallisierter Makromoleküle Rosalind Franklin und ihr Doktorand Raymond Gosling einen Röntgenstrahl durch eine Art Kristall aus DNA. Dabei entstand auf einem Röntgenfilm das berühmte Foto 51. Ich darf es hier wohl wegen des Urheberrechts nicht zeigen, aber man findet es in der Wikimedia. Eine aufwändige mathematische Datenanalyse lieferte Rosalind Franklin und Raymond Gosling Hinweise auf die Struktur der sogenannten B-Form der DNA, aber Rosalind Franklin interessierte sich mehr für die A-Form und ließ die Analyse der B-Form ertmal liegen. Als Rosalind Franklin kurz darauf das Institut verließ, sollte Raymond Gosling seine Forschungsergebnisse mit seinem neuen Betreuer Maurice Wilkins teilen, der Rosalind Franklin nicht mochte. Anfang 1952 zeigte Maurice Wilkins das Foto unerlaubterweise Franklins Konkurrenten, dem Biologen James Watson. Der erkannte sofort aufgrund des Fotos, dass die DNA die Form einer Helix haben musste, denn sein Forschungspartner, der Physiker und theoretische Molekularbiologe Francis Crick hatte bereits veröffentlicht, welches Bild eine Röntgenstrukturanalyse ergeben müsste, wenn die DNA die Form einer Helix bzw. Doppelhelix hätte.
Francis Crick und James Watson ließen sich sofort in der Institutswerkstatt aus Aluminium-Blechen und Draht Modelle der 4 DNA-Nukleobase basteln, um damit auszuprobieren, wie eine doppelspiralige DNA aussehen könnte.
| Das Foto zeigt ein Thymin-Modell aus Aluminium-Blech und Draht. Mit solchen Modellen bastelten Francis Crick und sein junger Kollege James Watson 1953 ihr berühmtes Modell der DNA-Doppelhelix. |

|
| Science Museum London / Science and Society Picture Library, CC BY-SA 2.0 Deed |
Das Ergebnis war ihr für die Genetik extrem wichtige Modell der DNA-Doppelhelix.
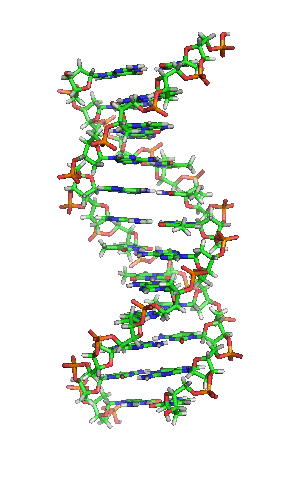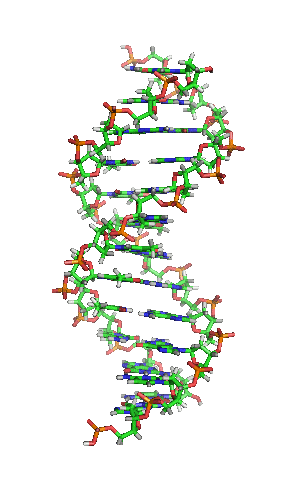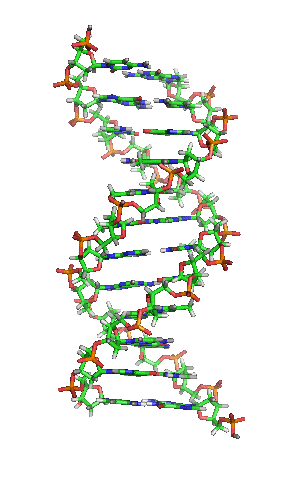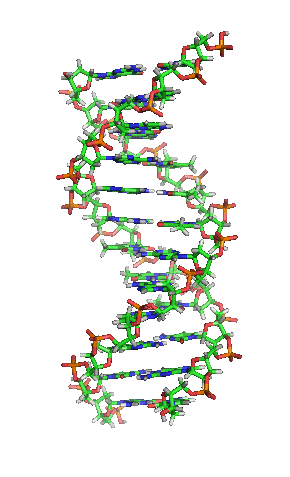
| animiertes Schema der DNA-Doppelhelix in ihrer sogenannten B-Form |
|---|
|
| Richard Wheeler, CC BY-SA 3.0 |
Auf einer eigenen Seite kann man sich mittels vierer selbst manipulierbarer, dreidimensionaler JSmol-Darstellungen die Strukturen verschiedener Nukleinsäuren von allen Seiten ansehen und diese Nukleinsäure-Moleküle dadurch besser verstehen.
DNA ist das Erbmaterial aller Prokaryoten und Eukaryoten. Die spezielle Struktur der DNA macht es möglich, in ihr Erbinformationen zu speichern und Kopien davon zu machen. Der Grund für die Kopierfähigkeit der DNA ist ihre Doppelsträngigkeit. Denn die beiden Stränge sind komplementär.
Weil der Zucker Desoxyribose und die Phosphat-Gruppe bei allen DNA-Nukleotiden gleich sind und nur das Rückrat der DNA bilden, steckt die Information in der Reihenfolge (Sequenz) der Nukleobasen Adenin, Cytosin, Guanin und Thymin. Diese Namen kann man sich schon leichter merken und zudem mit A, C, G und T abkürzen. Jeweils A und T sowie C und G bilden die unten rot gestrichelt dargestellten, durch Wasserstoffbrückenbindungen verbundenen Basenpaare.
Die folgenden beiden Bilder zeigen, dass die beiden Stränge der DNA eine Doppelhelix zwei umeinander gewundenen Helices bilden. Gut zu erkennen sind außerdem einzelne Nukleotide, in denen die Phosphor-Atome orange markiert sind und jeweils zwischen zwei Desoxyribose-Ringen liegen. Relativ locker miteinander verbunden sind die beiden DNA-Stränge über gestrichelt gezeichnete Wasserstoffbrückenbindungen zwischen den Nukleobase der Desoxyribonukleotide.
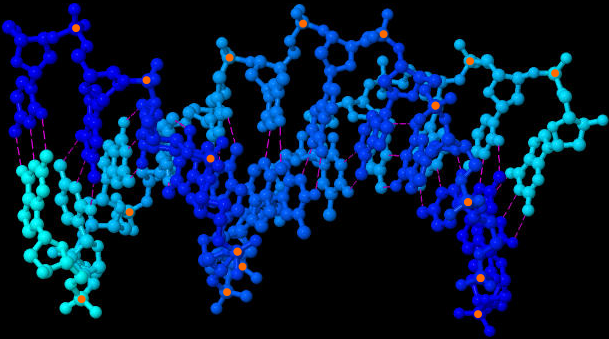
| Molekül-Struktur der DNA-Doppelhelix (JSmol-3D-Modell) | |
|---|---|
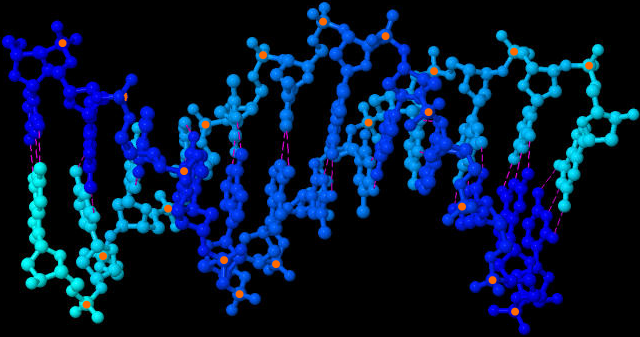 | |
| Rechts oben erkennt man die ringförmigen Desoxyribose-Moleküle und dazwischen je ein Phosphat-Molekül. Sich abwechselnd bilden sie das Rückrat der DNA. Im rechten Winkel dazu stehen die Basen (Nukleobasen). Gestrichelt sieht man die Wasserstoffbrückenbindungen zwischen den Nukleobasen. Sie verbinden die beiden DNA-Stränge der DNA-Doppelhelix. | |
 | |
| Roland Heynkes, CC BY-SA-4.0 | |
| Beide Bilder zeigen die DNA-Doppelhelix aus etwas unterschiedlichen Blickwinkeln, damit man die Struktur besser verstehen kann. Gestrichelt sind die Wasserstoffbrückenbindungen angedeutet. Zur besseren Orientierung habe ich alle sichtbaren Phosphor-Atome orange markiert. Erstellt habe ich die Bilder mit dem Java-Programm Jmol und den Koordinaten der Sequenz 1BNA der frei zugänglichen Protein Data Bank und dem darin als Option angebotenen Jmol-applet des Open Source Java Viewer for chemical structures in 3D. Diese Ergebnisse meiner Nutzung frei verfügbarer Daten und Programme dürfen selbstverständlich ebenfalls von jedem völlig frei genutzt werden. | |
Wie die in viele handliche Bände (Bücher) unterteilten großen Enzyklopädien oder Lexika ist auch das insgesamt schätzungsweise 1,8 Meter lange menschliche Genom unterteilt in 23 Chromosomen vom Vater und 23 Chromosomen von der Mutter. Die Chromosomen bestehen aus langen DNA-Fäden und vielen Proteinen. Vor einer Teilung des Zellkerns enthalten die Chromosomen zwei DNA-Doppelstränge und heißen deshalb 2-Chromatiden-Chromosomen oder Doppelchromosomen. Nach erfolgter Kernteilung enthält jedes Chromosom nur noch ein Chromatid und heißt darum 1-Chromatid-Chromosom.
Jeweils 8 Histon-Proteine bilden einen Komplex, um den herum ein kurzes Stück des unglaublich langen Riesenmoleküls DNA gewickelt wird. Jede dieser Verpackungseinheiten aus DNA und Histon-Proteinen nennt man Nukleosom.
| Nukleosom 1AOI |
|---|
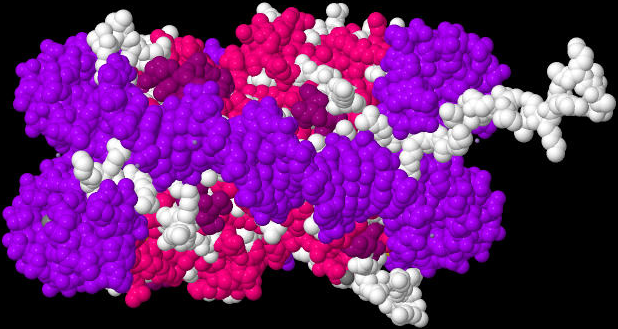 |
| Das von mir mit Hilfe der Daten der internationalen Protein Data Bank und dem Java-Programm Jmol erzeugte Bild zeigt ein Nukleosom von der Seite, damit man sieht, wie die lila gefärbte DNA fast zweimal um die 8 Histon-Proteine herum gewickelt ist. |
Weniger realistisch, aber leichter verständlich zeigt folgendes Schema die Struktur der DNA-Doppelhelix. Derart abstrahiert sieht doppelsträngige DNA aus wie eine spiralig verdrehte Strickleiter.
| Strickleiter-Modell der DNA-Doppelhelix | |
|---|---|
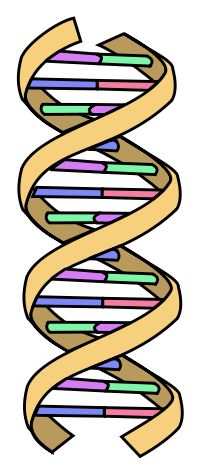 |
Die Nukleotide sind in den Nucleinsäuren (DNA und RNA) so miteinander verbunden, dass eine Art Rückgrat oder Leiterholm entsteht, in welchem sich der Zucker und die Phosphorsäure immer abwechseln. Von diesem Leiterholm stehen die verschiedenen Basen ab. Die RNA ist damit schon vollständig beschrieben, aber bei der DNA steht dem Leiterholm mit seinen abstehenden Basen ein zweiter Holm gegenüber, dessen Basen über Wasserstoffbrückenbindungen mit jeweils einer Base der anderen Seite verbunden sind. So bilden die beiden über ihre Basen verbundenen Holme eine Art Leiter oder Strickleiter. Man sieht außerdem, wie sich die beiden Holme spiralig um einander winden. Weil man jeden einzelnen auch als Helix bezeichnen kann, nennt man den DNA-Doppelstrang auch Doppelhelix. Der Durchmesser der Doppelhelix beträgt nur ungefähr 2 Nanometer, während die Gesamtlänge der DNA in den 46 1-Chromatid-Chromosomen einer einzigen menschlichen Zelle etwa 1,8 Meter beträgt. |
| Dieses vereinfachte Modell wurde von einem anonymen Schweizer der public domain geschenkt. | |
Zwei der drei Komponenten eines Nukleotids dienen in den Nukleinsäuren nur der Bildung eines langen, stabilen Rückrats. Zu diesem Zweck wechseln sich die Phosphatgruppe und die Desoxyribose (in DNA) bzw. Ribose (in RNA) einfach nur immer wieder ab. Informationen lassen sich so nicht speichern. Im Gegensatz dazu lassen sich in der Reihenfolge (Sequenz) der Basen sehr wohl Informationen codieren. Das funktioniert im Grunde genauso wie in diesem Lerntext, dessen Informationen ebenfalls in der (Sequenz) der Buchstaben codiert sind. Was allerdings einen DNA-Doppelstrang als Informationsträger von einem menschlichen Text unterscheidet, das ist die Basenpaarung. Denn in der DNA steht jeder Base des einen DNA-Stranges eine in Form und Größe genau dazu passende Base des Gegenstranges gegenüber. Passende Basenpaare bilden nur Adenin mit Thymin und Cytosin mit Guanin. Kennt man die Sequenz des einen DNA-Stranges, dann kennt man deshalb immer auch die Sequenz seines Gegenstranges. Und trennt man die beiden Stränge, dann ist es im Prinzip ganz einfach, zwei neue Gegenstränge aufzubauen. Denn frei herum schwimmende Nukleotide finden von selbst ihre passenden Partner und müssen nur noch durch ein Enzym miteinander verbunden werden. Nach diesem Prinzip werden mRNAs als Kopien aktiver Gene hergestellt und vor jeder Zellteilung die DNA-Doppelstränge verdoppelt. Und wird beispielsweise durch Röntgen- oder UV-Strahlung eine Base zerstört, dann kann sie von winzigen Reparatur-Enzymen entfernt und mit Hilfe des Gegenstranges durch eine passende neue ersetzt werden.
| DNA-Basenpaarungen | |
|---|---|
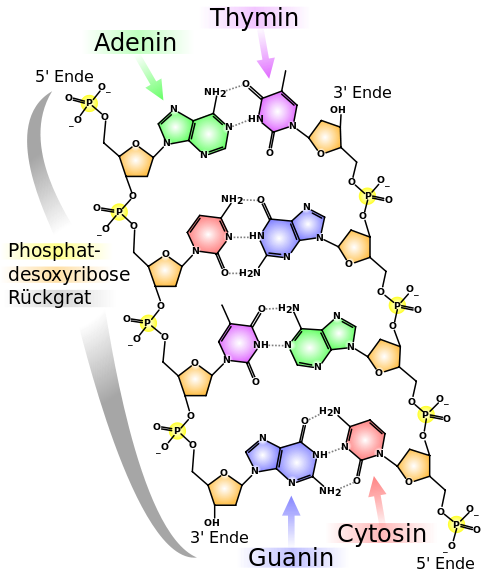 |
In der DNA stehen sich immer nur Adenin und Thymin oder Cytosin und Guanin gegenüber. Man spricht von sich ergänzenden oder komplementären Basenpaaren. Dabei sind Adenin und Thymin jeweils durch 2 Wasserstoffbrückenbindungen miteinander verbunden. Bei Cytosin und Guanin sind es drei. Cytosin und Guanin sind deshalb fester miteinander verbunden. Man erkennt in dieser Darstellung auch, dass die beiden Enden eines DNA-Einzelstranges (Holmes) nicht identisch sind. Man unterscheidet zwischen einem 5'-Ende und einem 3'-Ende. Dabei steht immer ein 5'-Ende des einen Einzelstranges einem 3'-Ende des Gegenstranges gegenüber. Aus diesem Aufbau ergibt sich, dass sich die Sequenz des einen Stranges automatisch aus der Sequenz des Gegenstranges ergibt. Für die genetische Information reicht daher ein Strang aus. Der Gegenstrang schützt allerdings die DNA vor dem Zerfall und stellt quasi eine Sicherheitskopie dar. Wird ein Strang beschädigt, kann er durch den Vergleich mit dem unbeschädigten Gegenstrang repariert werden. Außerdem lässt diese Struktur der DNA das Potential erkennen, Kopien von DNA-Einzelsträngen herzustellen. Diese Eigenschaft der DNA wird zur DNA-Verdopplung vor einer Zellteilung sowie zur Produktion von RNA-Kopien genutzt. Letzteres nennt man Transcription, denn im Grunde wird die DNA-Vorlage Buchstabe für Buchstabe abgeschrieben. Die Buchstaben sehen nur ein wenig anders aus. |
| Madeleine Price Ball, CC BY-SA 3.0 | |
Hier geht es mit dem Link zum Lerntext: "Vom Gen zum Protein".










{kind=link}
{kind=link}
{kind=link}
{kind=link}